* update docs
* introduce a temp enum to model an adjusted `BlockWrapper` and fix blob coupling
* fix compilation issue
* fix blob coupling in the network context
* review comments
## Issue Addressed
In #4027 I forgot to add the `parent_block_number` to the payload attributes SSE.
## Proposed Changes
Compute the parent block number while computing the pre-payload attributes. Pass it on to the SSE stream.
## Additional Info
Not essential for v3.5.1 as I suspect most builders don't need the `parent_block_root`. I would like to use it for my dummy no-op builder however.
## Issue Addressed
Add support for ipv6 and dual stack in lighthouse.
## Proposed Changes
From an user perspective, now setting an ipv6 address, optionally configuring the ports should feel exactly the same as using an ipv4 address. If listening over both ipv4 and ipv6 then the user needs to:
- use the `--listen-address` two times (ipv4 and ipv6 addresses)
- `--port6` becomes then required
- `--discovery-port6` can now be used to additionally configure the ipv6 udp port
### Rough list of code changes
- Discovery:
- Table filter and ip mode set to match the listening config.
- Ipv6 address, tcp port and udp port set in the ENR builder
- Reported addresses now check which tcp port to give to libp2p
- LH Network Service:
- Can listen over Ipv6, Ipv4, or both. This uses two sockets. Using mapped addresses is disabled from libp2p and it's the most compatible option.
- NetworkGlobals:
- No longer stores udp port since was not used at all. Instead, stores the Ipv4 and Ipv6 TCP ports.
- NetworkConfig:
- Update names to make it clear that previous udp and tcp ports in ENR were Ipv4
- Add fields to configure Ipv6 udp and tcp ports in the ENR
- Include advertised enr Ipv6 address.
- Add type to model Listening address that's either Ipv4, Ipv6 or both. A listening address includes the ip, udp port and tcp port.
- UPnP:
- Kept only for ipv4
- Cli flags:
- `--listen-addresses` now can take up to two values
- `--port` will apply to ipv4 or ipv6 if only one listening address is given. If two listening addresses are given it will apply only to Ipv4.
- `--port6` New flag required when listening over ipv4 and ipv6 that applies exclusively to Ipv6.
- `--discovery-port` will now apply to ipv4 and ipv6 if only one listening address is given.
- `--discovery-port6` New flag to configure the individual udp port of ipv6 if listening over both ipv4 and ipv6.
- `--enr-udp-port` Updated docs to specify that it only applies to ipv4. This is an old behaviour.
- `--enr-udp6-port` Added to configure the enr udp6 field.
- `--enr-tcp-port` Updated docs to specify that it only applies to ipv4. This is an old behaviour.
- `--enr-tcp6-port` Added to configure the enr tcp6 field.
- `--enr-addresses` now can take two values.
- `--enr-match` updated behaviour.
- Common:
- rename `unused_port` functions to specify that they are over ipv4.
- add functions to get unused ports over ipv6.
- Testing binaries
- Updated code to reflect network config changes and unused_port changes.
## Additional Info
TODOs:
- use two sockets in discovery. I'll get back to this and it's on https://github.com/sigp/discv5/pull/160
- lcli allow listening over two sockets in generate_bootnodes_enr
- add at least one smoke flag for ipv6 (I have tested this and works for me)
- update the book
## Proposed Changes
The current `/lighthouse/nat` implementation checks for _zero_ address updated messages, when it should check for a _non-zero_ number. This was spotted while debugging an issue on Discord where a user's ports weren't forwarded but `/lighthouse/nat` was still returning `true`.
## Issue Addressed
#3435
## Proposed Changes
Fire a warning with the path of JWT to be created when the path given by --execution-jwt is not found
Currently, the same error is logged if the jwt is found but doesn't match the execution client's jwt, and if no jwt was found at the given path. This makes it very hard to tell if you accidentally typed the wrong path, as a new jwt is created silently that won't match the execution client's jwt. So instead, it will now fire a warning stating that a jwt is being generated at the given path.
## Additional Info
In the future, it may be smarter to handle this case by adding an InvalidJWTPath member to the Error enum in lib.rs or auth.rs
that can be handled during upcheck()
This is my first PR and first project with rust. so thanks to anyone who looks at this for their patience and help!
Co-authored-by: Sebastian Richel <47844429+sebastianrich18@users.noreply.github.com>
## Proposed Changes
Two tiny updates to satisfy Clippy 1.68
Plus refactoring of the `http_api` into less complex types so the compiler can chew and digest them more easily.
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
* wip
* fix router
* arc the byroot responses we send
* add placeholder for blob verification
* respond to blobs by range and blobs by root request in the most horrible and gross way ever
* everything in sync is now unimplemented
* fix compiation issues
* http_pi change is very small, just add it
* remove ctrl-c ctrl-v's docs
## Issue Addressed
#4040
## Proposed Changes
- Add the `always_prefer_builder_payload` field to `Config` in `beacon_node/client/src/config.rs`.
- Add that same field to `Inner` in `beacon_node/execution_layer/src/lib.rs`
- Modify the logic for picking the payload in `beacon_node/execution_layer/src/lib.rs`
- Add the `always-prefer-builder-payload` flag to the beacon node CLI
- Test the new flags in `lighthouse/tests/beacon_node.rs`
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
NA
## Proposed Changes
In #4024 we added metrics to expose the latency measurements from a VC to each BN. Whilst playing with these new metrics on our infra I realised it would be great to have a single metric to make sure that the primary BN for each VC has a reasonable latency. With the current "metrics for all BNs" it's hard to tell which is the primary.
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
- Adds a `WARN` statement for Capella, just like the previous forks.
- Adds a hint message to all those WARNs to suggest the user update the BN or VC.
## Additional Info
NA
## Proposed Changes
Fix the cargo audit failure caused by [RUSTSEC-2023-0018](https://rustsec.org/advisories/RUSTSEC-2023-0018) which we were exposed to via `tempfile`.
## Additional Info
I've held back the libp2p crate for now because it seemed to introduce another duplicate dependency on libp2p-core, for a total of 3 copies. Maybe that's fine, but we can sort it out later.
## Issue Addressed
Closes#3963 (hopefully)
## Proposed Changes
Compute attestation selection proofs gradually each slot rather than in a single `join_all` at the start of each epoch. On a machine with 5k validators this replaces 5k tasks signing 5k proofs with 1 task that signs 5k/32 ~= 160 proofs each slot.
Based on testing with Goerli validators this seems to reduce the average time to produce a signature by preventing Tokio and the OS from falling over each other trying to run hundreds of threads. My testing so far has been with local keystores, which run on a dynamic pool of up to 512 OS threads because they use [`spawn_blocking`](https://docs.rs/tokio/1.11.0/tokio/task/fn.spawn_blocking.html) (and we haven't changed the default).
An earlier version of this PR hyper-optimised the time-per-signature metric to the detriment of the entire system's performance (see the reverted commits). The current PR is conservative in that it avoids touching the attestation service at all. I think there's more optimising to do here, but we can come back for that in a future PR rather than expanding the scope of this one.
The new algorithm for attestation selection proofs is:
- We sign a small batch of selection proofs each slot, for slots up to 8 slots in the future. On average we'll sign one slot's worth of proofs per slot, with an 8 slot lookahead.
- The batch is signed halfway through the slot when there is unlikely to be contention for signature production (blocks are <4s, attestations are ~4-6 seconds, aggregates are 8s+).
## Performance Data
_See first comment for updated graphs_.
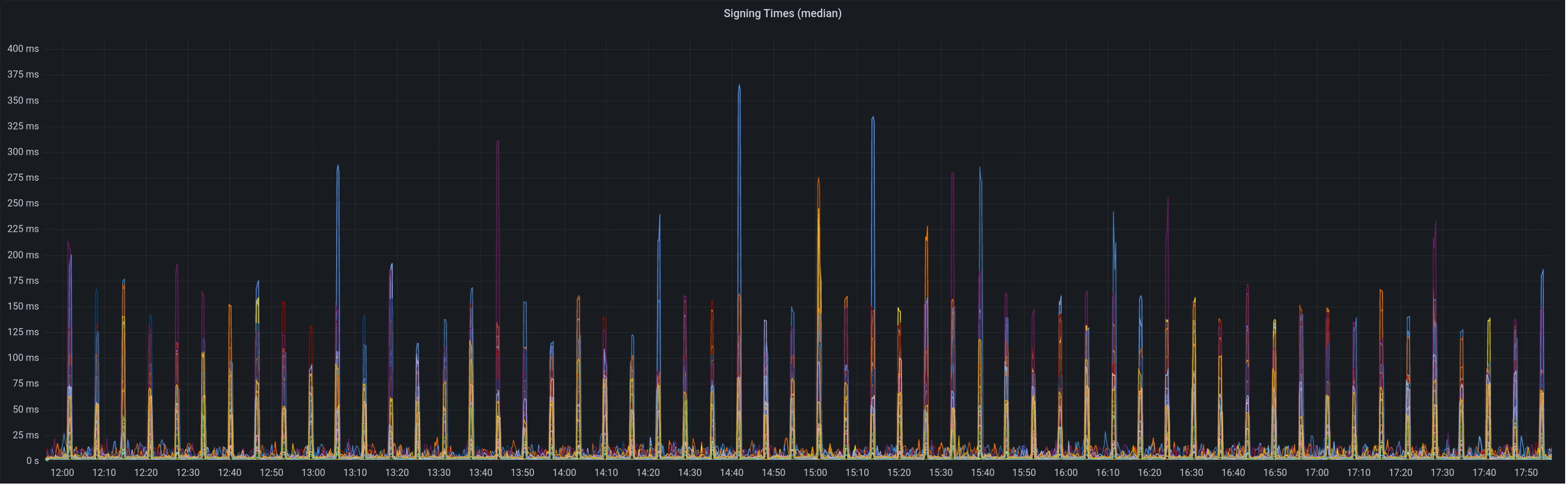
Graph of median signing times before this PR:
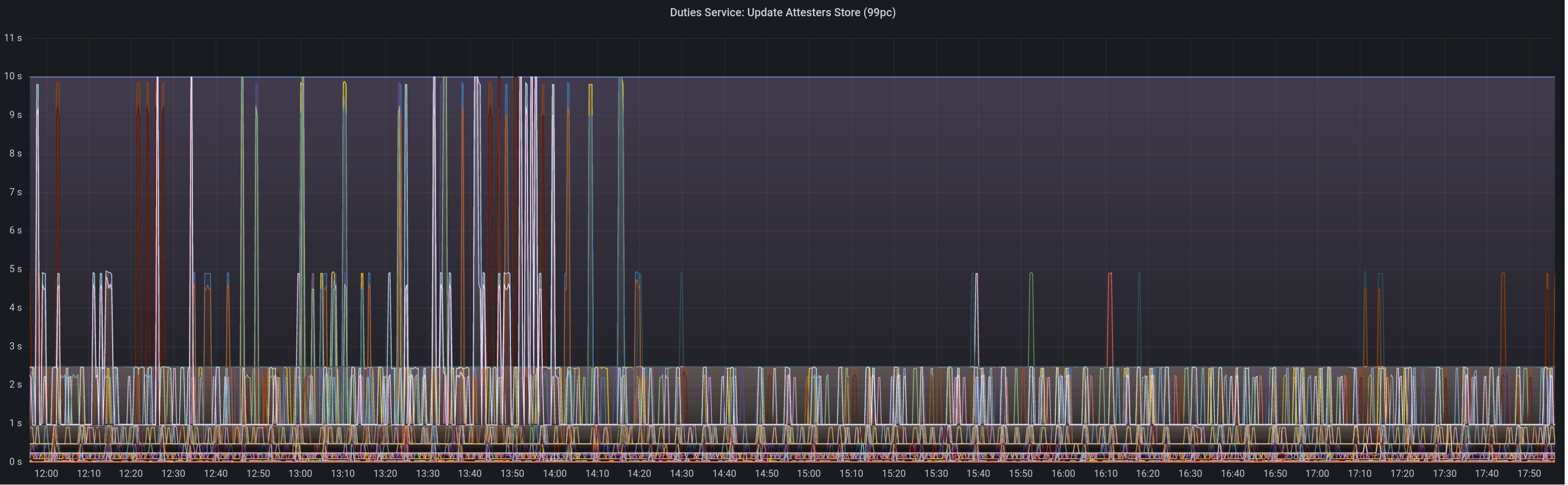
Graph of update attesters metric (includes selection proof signing) before this PR:
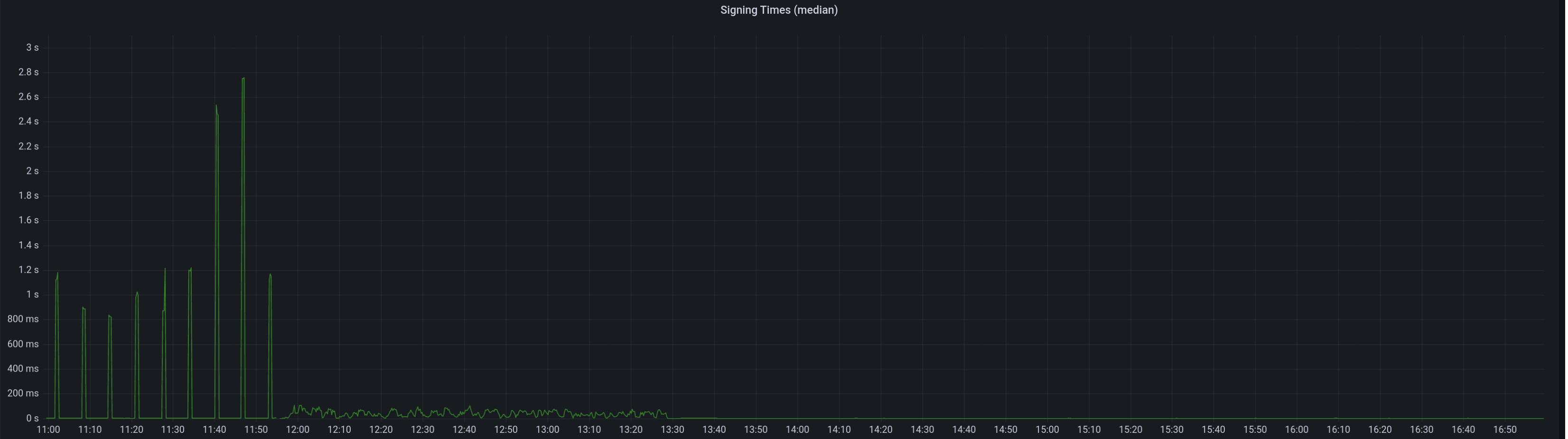
Median signing time after this PR (prototype from 12:00, updated version from 13:30):
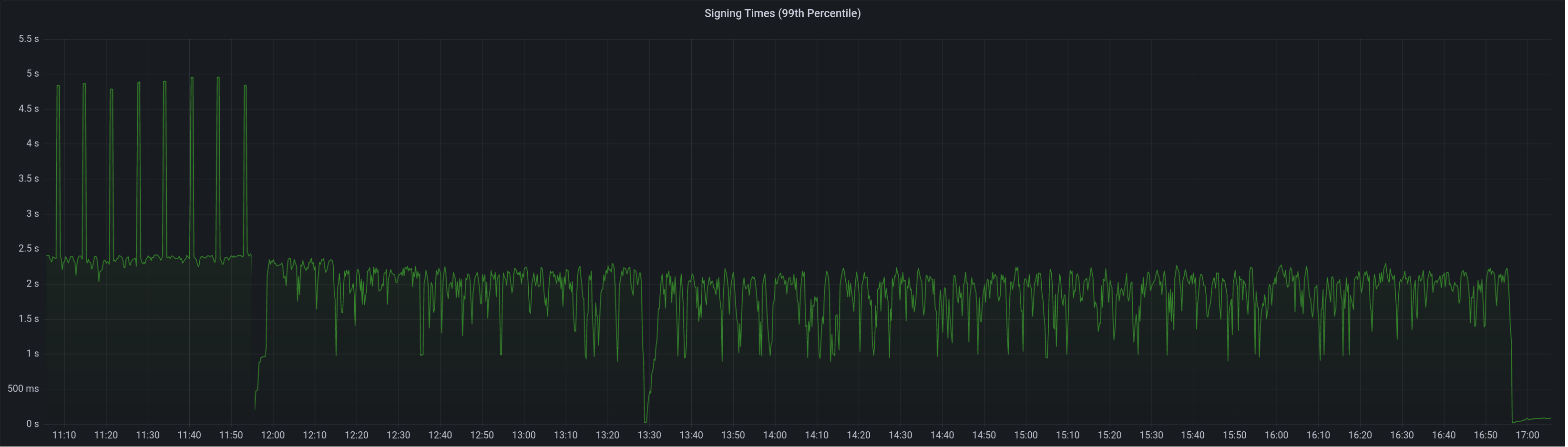
99th percentile on signing times (bounded attestation signing from 16:55, now removed):
Attester map update timing after this PR:
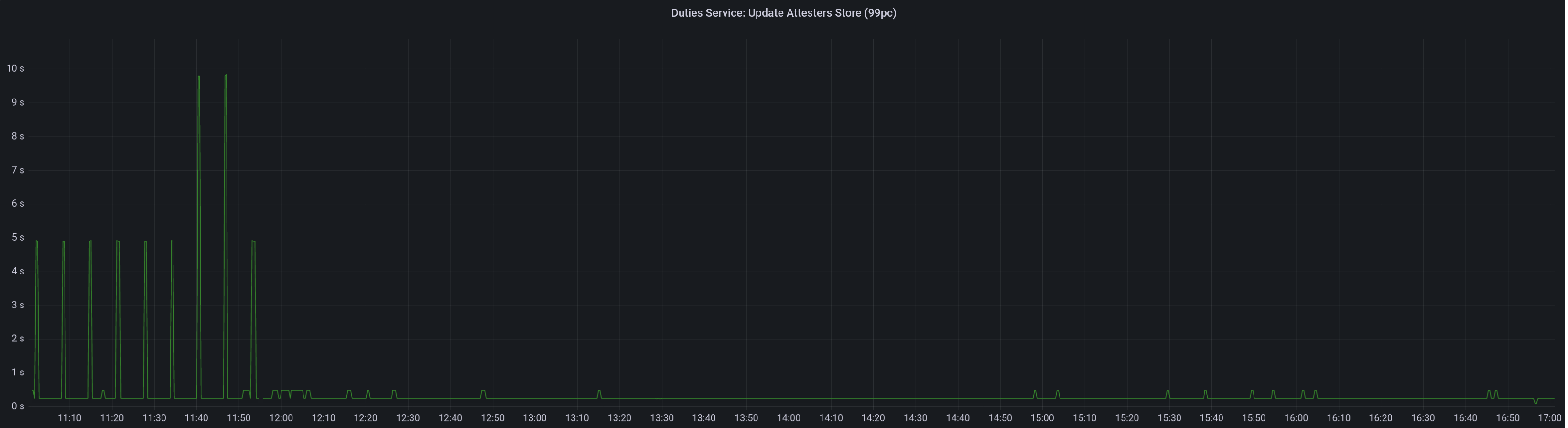
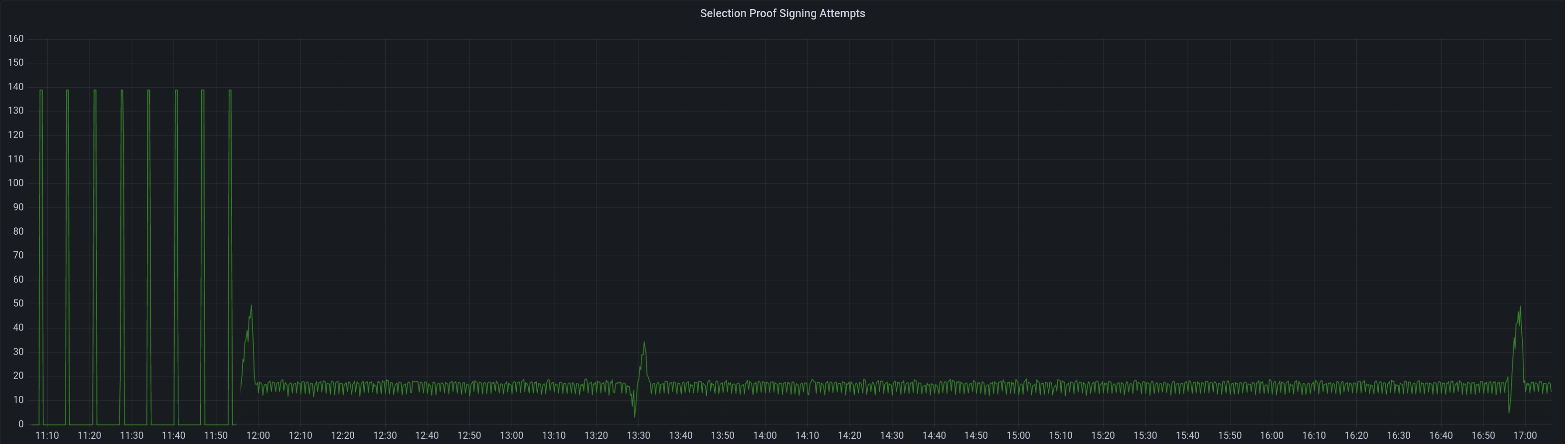
Selection proof signings per second change:
## Link to late blocks
I believe this is related to the slow block signings because logs from Stakely in #3963 show these two logs almost 5 seconds apart:
> Feb 23 18:56:23.978 INFO Received unsigned block, slot: 5862880, service: block, module: validator_client::block_service:393
> Feb 23 18:56:28.552 INFO Publishing signed block, slot: 5862880, service: block, module: validator_client::block_service:416
The only thing that happens between those two logs is the signing of the block:
0fb58a680d/validator_client/src/block_service.rs (L410-L414)
Helpfully, Stakely noticed this issue without any Lighthouse BNs in the mix, which pointed to a clear issue in the VC.
## TODO
- [x] Further testing on testnet infrastructure.
- [x] Make the attestation signing parallelism configurable.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}