## Issue Addressed
#3724
## Proposed Changes
Exposes certain `validator_monitor` as an endpoint on the HTTP API. Will only return metrics for validators which are actively being monitored.
### Usage
```bash
curl -X GET "http://localhost:5052/lighthouse/ui/validator_metrics" -H "accept: application/json" | jq
```
```json
{
"data": {
"validators": {
"12345": {
"attestation_hits": 10,
"attestation_misses": 0,
"attestation_hit_percentage": 100,
"attestation_head_hits": 10,
"attestation_head_misses": 0,
"attestation_head_hit_percentage": 100,
"attestation_target_hits": 5,
"attestation_target_misses": 5,
"attestation_target_hit_percentage": 50
}
}
}
}
```
## Additional Info
Based on #3756 which should be merged first.
## Issue Addressed
#3704
## Proposed Changes
Adds is_syncing_finalized: bool parameter for block verification functions. Sets the payload_verification_status to Optimistic if is_syncing_finalized is true. Uses SyncState in NetworkGlobals in BeaconProcessor to retrieve the syncing status.
## Additional Info
I could implement FinalizedSignatureVerifiedBlock if you think it would be nicer.
## Summary
The deposit cache now has the ability to finalize deposits. This will cause it to drop unneeded deposit logs and hashes in the deposit Merkle tree that are no longer required to construct deposit proofs. The cache is finalized whenever the latest finalized checkpoint has a new `Eth1Data` with all deposits imported.
This has three benefits:
1. Improves the speed of constructing Merkle proofs for deposits as we can just replay deposits since the last finalized checkpoint instead of all historical deposits when re-constructing the Merkle tree.
2. Significantly faster weak subjectivity sync as the deposit cache can be transferred to the newly syncing node in compressed form. The Merkle tree that stores `N` finalized deposits requires a maximum of `log2(N)` hashes. The newly syncing node then only needs to download deposits since the last finalized checkpoint to have a full tree.
3. Future proofing in preparation for [EIP-4444](https://eips.ethereum.org/EIPS/eip-4444) as execution nodes will no longer be required to store logs permanently so we won't always have all historical logs available to us.
## More Details
Image to illustrate how the deposit contract merkle tree evolves and finalizes along with the resulting `DepositTreeSnapshot`

## Other Considerations
I've changed the structure of the `SszDepositCache` so once you load & save your database from this version of lighthouse, you will no longer be able to load it from older versions.
Co-authored-by: ethDreamer <37123614+ethDreamer@users.noreply.github.com>
## Issue Addressed
NA
## Proposed Changes
This PR removes duplicated block root computation.
Computing the `SignedBeaconBlock::canonical_root` has become more expensive since the merge as we need to compute the merke root of each transaction inside an `ExecutionPayload`.
Computing the root for [a mainnet block](https://beaconcha.in/slot/4704236) is taking ~10ms on my i7-8700K CPU @ 3.70GHz (no sha extensions). Given that our median seen-to-imported time for blocks is presently 300-400ms, removing a few duplicated block roots (~30ms) could represent an easy 10% improvement. When we consider that the seen-to-imported times include operations *after* the block has been placed in the early attester cache, we could expect the 30ms to be more significant WRT our seen-to-attestable times.
## Additional Info
NA
## Issue Addressed
Add a flag that can increase count unrealized strictness, defaults to false
## Proposed Changes
Please list or describe the changes introduced by this PR.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: realbigsean <seananderson33@gmail.com>
Co-authored-by: sean <seananderson33@gmail.com>
## Issue Addressed
#3032
## Proposed Changes
Pause sync when ee is offline. Changes include three main parts:
- Online/offline notification system
- Pause sync
- Resume sync
#### Online/offline notification system
- The engine state is now guarded behind a new struct `State` that ensures every change is correctly notified. Notifications are only sent if the state changes. The new `State` is behind a `RwLock` (as before) as the synchronization mechanism.
- The actual notification channel is a [tokio::sync::watch](https://docs.rs/tokio/latest/tokio/sync/watch/index.html) which ensures only the last value is in the receiver channel. This way we don't need to worry about message order etc.
- Sync waits for state changes concurrently with normal messages.
#### Pause Sync
Sync has four components, pausing is done differently in each:
- **Block lookups**: Disabled while in this state. We drop current requests and don't search for new blocks. Block lookups are infrequent and I don't think it's worth the extra logic of keeping these and delaying processing. If we later see that this is required, we can add it.
- **Parent lookups**: Disabled while in this state. We drop current requests and don't search for new parents. Parent lookups are even less frequent and I don't think it's worth the extra logic of keeping these and delaying processing. If we later see that this is required, we can add it.
- **Range**: Chains don't send batches for processing to the beacon processor. This is easily done by guarding the channel to the beacon processor and giving it access only if the ee is responsive. I find this the simplest and most powerful approach since we don't need to deal with new sync states and chain segments that are added while the ee is offline will follow the same logic without needing to synchronize a shared state among those. Another advantage of passive pause vs active pause is that we can still keep track of active advertised chain segments so that on resume we don't need to re-evaluate all our peers.
- **Backfill**: Not affected by ee states, we don't pause.
#### Resume Sync
- **Block lookups**: Enabled again.
- **Parent lookups**: Enabled again.
- **Range**: Active resume. Since the only real pause range does is not sending batches for processing, resume makes all chains that are holding read-for-processing batches send them.
- **Backfill**: Not affected by ee states, no need to resume.
## Additional Info
**QUESTION**: Originally I made this to notify and change on synced state, but @pawanjay176 on talks with @paulhauner concluded we only need to check online/offline states. The upcheck function mentions extra checks to have a very up to date sync status to aid the networking stack. However, the only need the networking stack would have is this one. I added a TODO to review if the extra check can be removed
Next gen of #3094
Will work best with #3439
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
## Issue Addressed
NA
## Proposed Changes
Modifies `lcli skip-slots` and `lcli transition-blocks` allow them to source blocks/states from a beaconAPI and also gives them some more features to assist with benchmarking.
## Additional Info
Breaks the current `lcli skip-slots` and `lcli transition-blocks` APIs by changing some flag names. It should be simple enough to figure out the changes via `--help`.
Currently blocked on #3263.
## Issue Addressed
https://github.com/sigp/lighthouse/issues/3091
Extends https://github.com/sigp/lighthouse/pull/3062, adding pre-bellatrix block support on blinded endpoints and allowing the normal proposal flow (local payload construction) on blinded endpoints. This resulted in better fallback logic because the VC will not have to switch endpoints on failure in the BN <> Builder API, the BN can just fallback immediately and without repeating block processing that it shouldn't need to. We can also keep VC fallback from the VC<>BN API's blinded endpoint to full endpoint.
## Proposed Changes
- Pre-bellatrix blocks on blinded endpoints
- Add a new `PayloadCache` to the execution layer
- Better fallback-from-builder logic
## Todos
- [x] Remove VC transition logic
- [x] Add logic to only enable builder flow after Merge transition finalization
- [x] Tests
- [x] Fix metrics
- [x] Rustdocs
Co-authored-by: Mac L <mjladson@pm.me>
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
Add a flag that optionally enables unrealized vote tracking. Would like to test out on testnets and benchmark differences in methods of vote tracking. This PR includes a DB schema upgrade to enable to new vote tracking style.
Co-authored-by: realbigsean <sean@sigmaprime.io>
Co-authored-by: Paul Hauner <paul@paulhauner.com>
Co-authored-by: sean <seananderson33@gmail.com>
Co-authored-by: Mac L <mjladson@pm.me>
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/3189.
## Proposed Changes
- Always supply the justified block hash as the `safe_block_hash` when calling `forkchoiceUpdated` on the execution engine.
- Refactor the `get_payload` routine to use the new `ForkchoiceUpdateParameters` struct rather than just the `finalized_block_hash`. I think this is a nice simplification and that the old way of computing the `finalized_block_hash` was unnecessary, but if anyone sees reason to keep that approach LMK.
## Issue Addressed
Resolves#3249
## Proposed Changes
Log merge related parameters and EE status in the beacon notifier before the merge.
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Overview
This rather extensive PR achieves two primary goals:
1. Uses the finalized/justified checkpoints of fork choice (FC), rather than that of the head state.
2. Refactors fork choice, block production and block processing to `async` functions.
Additionally, it achieves:
- Concurrent forkchoice updates to the EL and cache pruning after a new head is selected.
- Concurrent "block packing" (attestations, etc) and execution payload retrieval during block production.
- Concurrent per-block-processing and execution payload verification during block processing.
- The `Arc`-ification of `SignedBeaconBlock` during block processing (it's never mutated, so why not?):
- I had to do this to deal with sending blocks into spawned tasks.
- Previously we were cloning the beacon block at least 2 times during each block processing, these clones are either removed or turned into cheaper `Arc` clones.
- We were also `Box`-ing and un-`Box`-ing beacon blocks as they moved throughout the networking crate. This is not a big deal, but it's nice to avoid shifting things between the stack and heap.
- Avoids cloning *all the blocks* in *every chain segment* during sync.
- It also has the potential to clean up our code where we need to pass an *owned* block around so we can send it back in the case of an error (I didn't do much of this, my PR is already big enough 😅)
- The `BeaconChain::HeadSafetyStatus` struct was removed. It was an old relic from prior merge specs.
For motivation for this change, see https://github.com/sigp/lighthouse/pull/3244#issuecomment-1160963273
## Changes to `canonical_head` and `fork_choice`
Previously, the `BeaconChain` had two separate fields:
```
canonical_head: RwLock<Snapshot>,
fork_choice: RwLock<BeaconForkChoice>
```
Now, we have grouped these values under a single struct:
```
canonical_head: CanonicalHead {
cached_head: RwLock<Arc<Snapshot>>,
fork_choice: RwLock<BeaconForkChoice>
}
```
Apart from ergonomics, the only *actual* change here is wrapping the canonical head snapshot in an `Arc`. This means that we no longer need to hold the `cached_head` (`canonical_head`, in old terms) lock when we want to pull some values from it. This was done to avoid deadlock risks by preventing functions from acquiring (and holding) the `cached_head` and `fork_choice` locks simultaneously.
## Breaking Changes
### The `state` (root) field in the `finalized_checkpoint` SSE event
Consider the scenario where epoch `n` is just finalized, but `start_slot(n)` is skipped. There are two state roots we might in the `finalized_checkpoint` SSE event:
1. The state root of the finalized block, which is `get_block(finalized_checkpoint.root).state_root`.
4. The state root at slot of `start_slot(n)`, which would be the state from (1), but "skipped forward" through any skip slots.
Previously, Lighthouse would choose (2). However, we can see that when [Teku generates that event](de2b2801c8/data/beaconrestapi/src/main/java/tech/pegasys/teku/beaconrestapi/handlers/v1/events/EventSubscriptionManager.java (L171-L182)) it uses [`getStateRootFromBlockRoot`](de2b2801c8/data/provider/src/main/java/tech/pegasys/teku/api/ChainDataProvider.java (L336-L341)) which uses (1).
I have switched Lighthouse from (2) to (1). I think it's a somewhat arbitrary choice between the two, where (1) is easier to compute and is consistent with Teku.
## Notes for Reviewers
I've renamed `BeaconChain::fork_choice` to `BeaconChain::recompute_head`. Doing this helped ensure I broke all previous uses of fork choice and I also find it more descriptive. It describes an action and can't be confused with trying to get a reference to the `ForkChoice` struct.
I've changed the ordering of SSE events when a block is received. It used to be `[block, finalized, head]` and now it's `[block, head, finalized]`. It was easier this way and I don't think we were making any promises about SSE event ordering so it's not "breaking".
I've made it so fork choice will run when it's first constructed. I did this because I wanted to have a cached version of the last call to `get_head`. Ensuring `get_head` has been run *at least once* means that the cached values doesn't need to wrapped in an `Option`. This was fairly simple, it just involved passing a `slot` to the constructor so it knows *when* it's being run. When loading a fork choice from the store and a slot clock isn't handy I've just used the `slot` that was saved in the `fork_choice_store`. That seems like it would be a faithful representation of the slot when we saved it.
I added the `genesis_time: u64` to the `BeaconChain`. It's small, constant and nice to have around.
Since we're using FC for the fin/just checkpoints, we no longer get the `0x00..00` roots at genesis. You can see I had to remove a work-around in `ef-tests` here: b56be3bc2. I can't find any reason why this would be an issue, if anything I think it'll be better since the genesis-alias has caught us out a few times (0x00..00 isn't actually a real root). Edit: I did find a case where the `network` expected the 0x00..00 alias and patched it here: 3f26ac3e2.
You'll notice a lot of changes in tests. Generally, tests should be functionally equivalent. Here are the things creating the most diff-noise in tests:
- Changing tests to be `tokio::async` tests.
- Adding `.await` to fork choice, block processing and block production functions.
- Refactor of the `canonical_head` "API" provided by the `BeaconChain`. E.g., `chain.canonical_head.cached_head()` instead of `chain.canonical_head.read()`.
- Wrapping `SignedBeaconBlock` in an `Arc`.
- In the `beacon_chain/tests/block_verification`, we can't use the `lazy_static` `CHAIN_SEGMENT` variable anymore since it's generated with an async function. We just generate it in each test, not so efficient but hopefully insignificant.
I had to disable `rayon` concurrent tests in the `fork_choice` tests. This is because the use of `rayon` and `block_on` was causing a panic.
Co-authored-by: Mac L <mjladson@pm.me>
## Issue Addressed
Upcoming spec change https://github.com/ethereum/consensus-specs/pull/2878
## Proposed Changes
1. Run fork choice at the start of every slot, and wait for this run to complete before proposing a block.
2. As an optimisation, also run fork choice 3/4 of the way through the slot (at 9s), _dequeueing attestations for the next slot_.
3. Remove the fork choice run from the state advance timer that occurred before advancing the state.
## Additional Info
### Block Proposal Accuracy
This change makes us more likely to propose on top of the correct head in the presence of re-orgs with proposer boost in play. The main scenario that this change is designed to address is described in the linked spec issue.
### Attestation Accuracy
This change _also_ makes us more likely to attest to the correct head. Currently in the case of a skipped slot at `slot` we only run fork choice 9s into `slot - 1`. This means the attestations from `slot - 1` aren't taken into consideration, and any boost applied to the block from `slot - 1` is not removed (it should be). In the language of the linked spec issue, this means we are liable to attest to C, even when the majority voting weight has already caused a re-org to B.
### Why remove the call before the state advance?
If we've run fork choice at the start of the slot then it has already dequeued all the attestations from the previous slot, which are the only ones eligible to influence the head in the current slot. Running fork choice again is unnecessary (unless we run it for the next slot and try to pre-empt a re-org, but I don't currently think this is a great idea).
### Performance
Based on Prater testing this adds about 5-25ms of runtime to block proposal times, which are 500-1000ms on average (and spike to 5s+ sometimes due to state handling issues 😢 ). I believe this is a small enough penalty to enable it by default, with the option to disable it via the new flag `--fork-choice-before-proposal-timeout 0`. Upcoming work on block packing and state representation will also reduce block production times in general, while removing the spikes.
### Implementation
Fork choice gets invoked at the start of the slot via the `per_slot_task` function called from the slot timer. It then uses a condition variable to signal to block production that fork choice has been updated. This is a bit funky, but it seems to work. One downside of the timer-based approach is that it doesn't happen automatically in most of the tests. The test added by this PR has to trigger the run manually.
## Proposed Changes
Allow Lighthouse to speculatively create blocks via the `/eth/v1/validators/blocks` endpoint by optionally skipping the RANDAO verification that we introduced in #2740. When `verify_randao=false` is passed as a query parameter the `randao_reveal` is not required to be present, and if present will only be lightly checked (must be a valid BLS sig). If `verify_randao` is omitted it defaults to true and Lighthouse behaves exactly as it did previously, hence this PR is backwards-compatible.
I'd like to get this change into `unstable` pretty soon as I've got 3 projects building on top of it:
- [`blockdreamer`](https://github.com/michaelsproul/blockdreamer), which mocks block production every slot in order to fingerprint clients
- analysis of Lighthouse's block packing _optimality_, which uses `blockdreamer` to extract interesting instances of the attestation packing problem
- analysis of Lighthouse's block packing _performance_ (as in speed) on the `tree-states` branch
## Additional Info
Having tested `blockdreamer` with Prysm, Nimbus and Teku I noticed that none of them verify the randao signature on `/eth/v1/validator/blocks`. I plan to open a PR to the `beacon-APIs` repo anyway so that this parameter can be standardised in case the other clients add RANDAO verification by default in future.
## Issue Addressed
Resolves#2936
## Proposed Changes
Adds functionality for calling [`validator/prepare_beacon_proposer`](https://ethereum.github.io/beacon-APIs/?urls.primaryName=dev#/Validator/prepareBeaconProposer) in advance.
There is a `BeaconChain::prepare_beacon_proposer` method which, which called, computes the proposer for the next slot. If that proposer has been registered via the `validator/prepare_beacon_proposer` API method, then the `beacon_chain.execution_layer` will be provided the `PayloadAttributes` for us in all future forkchoiceUpdated calls. An artificial forkchoiceUpdated call will be created 4s before each slot, when the head updates and when a validator updates their information.
Additionally, I added strict ordering for calls from the `BeaconChain` to the `ExecutionLayer`. I'm not certain the `ExecutionLayer` will always maintain this ordering, but it's a good start to have consistency from the `BeaconChain`. There are some deadlock opportunities introduced, they are documented in the code.
## Additional Info
- ~~Blocked on #2837~~
Co-authored-by: realbigsean <seananderson33@GMAIL.com>
## Issue Addressed
NA
## Proposed Changes
Adds the functionality to allow blocks to be validated/invalidated after their import as per the [optimistic sync spec](https://github.com/ethereum/consensus-specs/blob/dev/sync/optimistic.md#how-to-optimistically-import-blocks). This means:
- Updating `ProtoArray` to allow flipping the `execution_status` of ancestors/descendants based on payload validity updates.
- Creating separation between `execution_layer` and the `beacon_chain` by creating a `PayloadStatus` struct.
- Refactoring how the `execution_layer` selects a `PayloadStatus` from the multiple statuses returned from multiple EEs.
- Adding testing framework for optimistic imports.
- Add `ExecutionBlockHash(Hash256)` new-type struct to avoid confusion between *beacon block roots* and *execution payload hashes*.
- Add `merge` to [`FORKS`](c3a793fd73/Makefile (L17)) in the `Makefile` to ensure we test the beacon chain with merge settings.
- Fix some tests here that were failing due to a missing execution layer.
## TODO
- [ ] Balance tests
Co-authored-by: Mark Mackey <mark@sigmaprime.io>
## Issue Addressed
This PR fixes the unnecessary `WARN Single block lookup failed` messages described here:
https://github.com/sigp/lighthouse/pull/2866#issuecomment-1008442640
## Proposed Changes
Add a new cache to the `BeaconChain` that tracks the block roots of blocks from before finalization. These could be blocks from the canonical chain (which might need to be read from disk), or old pre-finalization blocks that have been forked out.
The cache also stores a set of block roots for in-progress single block lookups, which duplicates some of the information from sync's `single_block_lookups` hashmap:
a836e180f9/beacon_node/network/src/sync/manager.rs (L192-L196)
On a live node you can confirm that the cache is working by grepping logs for the message: `Rejected attestation to finalized block`.
## Issue Addressed
NA
## Proposed Changes
Introduces a cache to attestation to produce atop blocks which will become the head, but are not fully imported (e.g., not inserted into the database).
Whilst attesting to a block before it's imported is rather easy, if we're going to produce that attestation then we also need to be able to:
1. Verify that attestation.
1. Respond to RPC requests for the `beacon_block_root`.
Attestation verification (1) is *partially* covered. Since we prime the shuffling cache before we insert the block into the early attester cache, we should be fine for all typical use-cases. However, it is possible that the cache is washed out before we've managed to insert the state into the database and then attestation verification will fail with a "missing beacon state"-type error.
Providing the block via RPC (2) is also partially covered, since we'll check the database *and* the early attester cache when responding a blocks-by-root request. However, we'll still omit the block from blocks-by-range requests (until the block lands in the DB). I *think* this is fine, since there's no guarantee that we return all blocks for those responses.
Another important consideration is whether or not the *parent* of the early attester block is available in the databse. If it were not, we might fail to respond to blocks-by-root request that are iterating backwards to collect a chain of blocks. I argue that *we will always have the parent of the early attester block in the database.* This is because we are holding the fork-choice write-lock when inserting the block into the early attester cache and we do not drop that until the block is in the database.
* Fix fork choice after rebase
* Remove paulhauner warp dep
* Fix fork choice test compile errors
* Assume fork choice payloads are valid
* Add comment
* Ignore new tests
* Fix error in test skipping
* Add payload verification status to fork choice
* Pass payload verification status to import_block
* Add valid back-propagation
* Add head safety status latch to API
* Remove ExecutionLayerStatus
* Add execution info to client notifier
* Update notifier logs
* Change use of "hash" to refer to beacon block
* Shutdown on invalid finalized block
* Tidy, add comments
* Fix failing FC tests
* Allow blocks with unsafe head
* Fix forkchoiceUpdate call on startup
* Reject some HTTP endpoints when EL is not ready
* Restrict more endpoints
* Add watchdog task
* Change scheduling
* Update to new schedule
* Add "syncing" concept
* Remove RequireSynced
* Add is_merge_complete to head_info
* Cache latest_head in Engines
* Call consensus_forkchoiceUpdate on startup
Added Execution Payload from Rayonism Fork
Updated new Containers to match Merge Spec
Updated BeaconBlockBody for Merge Spec
Completed updating BeaconState and BeaconBlockBody
Modified ExecutionPayload<T> to use Transaction<T>
Mostly Finished Changes for beacon-chain.md
Added some things for fork-choice.md
Update to match new fork-choice.md/fork.md changes
ran cargo fmt
Added Missing Pieces in eth2_libp2p for Merge
fix ef test
Various Changes to Conform Closer to Merge Spec
## Issue Addressed
Resolves#2545
## Proposed Changes
Adds the long-overdue EF tests for fork choice. Although we had pretty good coverage via other implementations that closely followed our approach, it is nonetheless important for us to implement these tests too.
During testing I found that we were using a hard-coded `SAFE_SLOTS_TO_UPDATE_JUSTIFIED` value rather than one from the `ChainSpec`. This caused a failure during a minimal preset test. This doesn't represent a risk to mainnet or testnets, since the hard-coded value matched the mainnet preset.
## Failing Cases
There is one failing case which is presently marked as `SkippedKnownFailure`:
```
case 4 ("new_finalized_slot_is_justified_checkpoint_ancestor") from /home/paul/development/lighthouse/testing/ef_tests/consensus-spec-tests/tests/minimal/phase0/fork_choice/on_block/pyspec_tests/new_finalized_slot_is_justified_checkpoint_ancestor failed with NotEqual:
head check failed: Got Head { slot: Slot(40), root: 0x9183dbaed4191a862bd307d476e687277fc08469fc38618699863333487703e7 } | Expected Head { slot: Slot(24), root: 0x105b49b51bf7103c182aa58860b039550a89c05a4675992e2af703bd02c84570 }
```
This failure is due to #2741. It's not a particularly high priority issue at the moment, so we fix it after merging this PR.
## Issue Addressed
Mitigates #1096
## Proposed Changes
Add a flag to the beacon node called `--disable-lock-timeouts` which allows opting out of lock timeouts.
The lock timeouts serve a dual purpose:
1. They prevent any single operation from hogging the lock for too long. When a timeout occurs it logs a nasty error which indicates that there's suboptimal lock use occurring, which we can then act on.
2. They allow deadlock detection. We're fairly sure there are no deadlocks left in Lighthouse anymore but the timeout locks offer a safeguard against that.
However, timeouts on locks are not without downsides:
They allow for the possibility of livelock, particularly on slower hardware. If lock timeouts keep failing spuriously the node can be prevented from making any progress, even if it would be able to make progress slowly without the timeout. One particularly concerning scenario which could occur would be if a DoS attack succeeded in slowing block signature verification times across the network, and all Lighthouse nodes got livelocked because they timed out repeatedly. This could also occur on just a subset of nodes (e.g. dual core VPSs or Raspberri Pis).
By making the behaviour runtime configurable this PR allows us to choose the behaviour we want depending on circumstance. I suspect that long term we could make the timeout-free approach the default (#2381 moves in this direction) and just enable the timeouts on our testnet nodes for debugging purposes. This PR conservatively leaves the default as-is so we can gain some more experience before switching the default.
## Issue Addressed
Closes#2528
## Proposed Changes
- Add `BlockTimesCache` to provide block timing information to `BeaconChain`. This allows additional metrics to be calculated for blocks that are set as head too late.
- Thread the `seen_timestamp` of blocks received from RPC responses (except blocks from syncing) through to the sync manager, similar to what is done for blocks from gossip.
## Additional Info
This provides the following additional metrics:
- `BEACON_BLOCK_OBSERVED_SLOT_START_DELAY_TIME`
- The delay between the start of the slot and when the block was first observed.
- `BEACON_BLOCK_IMPORTED_OBSERVED_DELAY_TIME`
- The delay between when the block was first observed and when the block was imported.
- `BEACON_BLOCK_HEAD_IMPORTED_DELAY_TIME`
- The delay between when the block was imported and when the block was set as head.
The metric `BEACON_BLOCK_IMPORTED_SLOT_START_DELAY_TIME` was removed.
A log is produced when a block is set as head too late, e.g.:
```
Aug 27 03:46:39.006 DEBG Delayed head block set_as_head_delay: Some(21.731066ms), imported_delay: Some(119.929934ms), observed_delay: Some(3.864596988s), block_delay: 4.006257988s, slot: 1931331, proposer_index: 24294, block_root: 0x937602c89d3143afa89088a44bdf4b4d0d760dad082abacb229495c048648a9e, service: beacon
```
## Issue Addressed
Closes#1891Closes#1784
## Proposed Changes
Implement checkpoint sync for Lighthouse, enabling it to start from a weak subjectivity checkpoint.
## Additional Info
- [x] Return unavailable status for out-of-range blocks requested by peers (#2561)
- [x] Implement sync daemon for fetching historical blocks (#2561)
- [x] Verify chain hashes (either in `historical_blocks.rs` or the calling module)
- [x] Consistency check for initial block + state
- [x] Fetch the initial state and block from a beacon node HTTP endpoint
- [x] Don't crash fetching beacon states by slot from the API
- [x] Background service for state reconstruction, triggered by CLI flag or API call.
Considered out of scope for this PR:
- Drop the requirement to provide the `--checkpoint-block` (this would require some pretty heavy refactoring of block verification)
Co-authored-by: Diva M <divma@protonmail.com>
## Issue Addressed
Closes#2526
## Proposed Changes
If the head block fails to decode on start up, do two things:
1. Revert all blocks between the head and the most recent hard fork (to `fork_slot - 1`).
2. Reset fork choice so that it contains the new head, and all blocks back to the new head's finalized checkpoint.
## Additional Info
I tweaked some of the beacon chain test harness stuff in order to make it generic enough to test with a non-zero slot clock on start-up. In the process I consolidated all the various `new_` methods into a single generic one which will hopefully serve all future uses 🤞
## Issue Addressed
- Resolves#2169
## Proposed Changes
Adds the `AttesterCache` to allow validators to produce attestations for older slots. Presently, some arbitrary restrictions can force validators to receive an error when attesting to a slot earlier than the present one. This can cause attestation misses when there is excessive load on the validator client or time sync issues between the VC and BN.
## Additional Info
NA
## Issue Addressed
NA
## Primary Change
When investigating memory usage, I noticed that retrieving a block from an early slot (e.g., slot 900) would cause a sharp increase in the memory footprint (from 400mb to 800mb+) which seemed to be ever-lasting.
After some investigation, I found that the reverse iteration from the head back to that slot was the likely culprit. To counter this, I've switched the `BeaconChain::block_root_at_slot` to use the forwards iterator, instead of the reverse one.
I also noticed that the networking stack is using `BeaconChain::root_at_slot` to check if a peer is relevant (`check_peer_relevance`). Perhaps the steep, seemingly-random-but-consistent increases in memory usage are caused by the use of this function.
Using the forwards iterator with the HTTP API alleviated the sharp increases in memory usage. It also made the response much faster (before it felt like to took 1-2s, now it feels instant).
## Additional Changes
In the process I also noticed that we have two functions for getting block roots:
- `BeaconChain::block_root_at_slot`: returns `None` for a skip slot.
- `BeaconChain::root_at_slot`: returns the previous root for a skip slot.
I unified these two functions into `block_root_at_slot` and added the `WhenSlotSkipped` enum. Now, the caller must be explicit about the skip-slot behaviour when requesting a root.
Additionally, I replaced `vec![]` with `Vec::with_capacity` in `store::chunked_vector::range_query`. I stumbled across this whilst debugging and made this modification to see what effect it would have (not much). It seems like a decent change to keep around, but I'm not concerned either way.
Also, `BeaconChain::get_ancestor_block_root` is unused, so I got rid of it 🗑️.
## Additional Info
I haven't also done the same for state roots here. Whilst it's possible and a good idea, it's more work since the fwds iterators are presently block-roots-specific.
Whilst there's a few places a reverse iteration of state roots could be triggered (e.g., attestation production, HTTP API), they're no where near as common as the `check_peer_relevance` call. As such, I think we should get this PR merged first, then come back for the state root iters. I made an issue here https://github.com/sigp/lighthouse/issues/2377.
## Issue Addressed
Closes#1787
## Proposed Changes
* Abstract the `ValidatorPubkeyCache` over a "backing" which is either a file (legacy), or the database.
* Implement a migration from schema v2 to schema v3, whereby the contents of the cache file are copied to the DB, and then the file is deleted. The next release to include this change must be a minor version bump, and we will need to warn users of the inability to downgrade (this is our first DB schema change since mainnet genesis).
* Move the schema migration code from the `store` crate into the `beacon_chain` crate so that it can access the datadir and the `ValidatorPubkeyCache`, etc. It gets injected back into the `store` via a closure (similar to what we do in fork choice).
## Issue Addressed
NA
## Problem this PR addresses
There's an issue where Lighthouse is banning a lot of peers due to the following sequence of events:
1. Gossip block 0xabc arrives ~200ms early
- It is propagated across the network, with respect to [`MAXIMUM_GOSSIP_CLOCK_DISPARITY`](https://github.com/ethereum/eth2.0-specs/blob/v1.0.0/specs/phase0/p2p-interface.md#why-is-there-maximum_gossip_clock_disparity-when-validating-slot-ranges-of-messages-in-gossip-subnets).
- However, it is not imported to our database since the block is early.
2. Attestations for 0xabc arrive, but the block was not imported.
- The peer that sent the attestation is down-voted.
- Each unknown-block attestation causes a score loss of 1, the peer is banned at -100.
- When the peer is on an attestation subnet there can be hundreds of attestations, so the peer is banned quickly (before the missed block can be obtained via rpc).
## Potential solutions
I can think of three solutions to this:
1. Wait for attestation-queuing (#635) to arrive and solve this.
- Easy
- Not immediate fix.
- Whilst this would work, I don't think it's a perfect solution for this particular issue, rather (3) is better.
1. Allow importing blocks with a tolerance of `MAXIMUM_GOSSIP_CLOCK_DISPARITY`.
- Easy
- ~~I have implemented this, for now.~~
1. If a block is verified for gossip propagation (i.e., signature verified) and it's within `MAXIMUM_GOSSIP_CLOCK_DISPARITY`, then queue it to be processed at the start of the appropriate slot.
- More difficult
- Feels like the best solution, I will try to implement this.
**This PR takes approach (3).**
## Changes included
- Implement the `block_delay_queue`, based upon a [`DelayQueue`](https://docs.rs/tokio-util/0.6.3/tokio_util/time/delay_queue/struct.DelayQueue.html) which can store blocks until it's time to import them.
- Add a new `DelayedImportBlock` variant to the `beacon_processor::WorkEvent` enum to handle this new event.
- In the `BeaconProcessor`, refactor a `tokio::select!` to a struct with an explicit `Stream` implementation. I experienced some issues with `tokio::select!` in the block delay queue and I also found it hard to debug. I think this explicit implementation is nicer and functionally equivalent (apart from the fact that `tokio::select!` randomly chooses futures to poll, whereas now we're deterministic).
- Add a testing framework to the `beacon_processor` module that tests this new block delay logic. I also tested a handful of other operations in the beacon processor (attns, slashings, exits) since it was super easy to copy-pasta the code from the `http_api` tester.
- To implement these tests I added the concept of an optional `work_journal_tx` to the `BeaconProcessor` which will spit out a log of events. I used this in the tests to ensure that things were happening as I expect.
- The tests are a little racey, but it's hard to avoid that when testing timing-based code. If we see CI failures I can revise. I haven't observed *any* failures due to races on my machine or on CI yet.
- To assist with testing I allowed for directly setting the time on the `ManualSlotClock`.
- I gave the `beacon_processor::Worker` a `Toolbox` for two reasons; (a) it avoids changing tons of function sigs when you want to pass a new object to the worker and (b) it seemed cute.
## Issue Addressed
NA
## Proposed Changes
Add an optimization to perform `per_slot_processing` from the *leading-edge* of block processing to the *trailing-edge*. Ultimately, this allows us to import the block at slot `n` faster because we used the tail-end of slot `n - 1` to perform `per_slot_processing`.
Additionally, add a "block proposer cache" which allows us to cache the block proposer for some epoch. Since we're now doing trailing-edge `per_slot_processing`, we can prime this cache with the values for the next epoch before those blocks arrive (assuming those blocks don't have some weird forking).
There were several ancillary changes required to achieve this:
- Remove the `state_root` field of `BeaconSnapshot`, since there's no need to know it on a `pre_state` and in all other cases we can just read it from `block.state_root()`.
- This caused some "dust" changes of `snapshot.beacon_state_root` to `snapshot.beacon_state_root()`, where the `BeaconSnapshot::beacon_state_root()` func just reads the state root from the block.
- Rename `types::ShuffingId` to `AttestationShufflingId`. I originally did this because I added a `ProposerShufflingId` struct which turned out to be not so useful. I thought this new name was more descriptive so I kept it.
- Address https://github.com/ethereum/eth2.0-specs/pull/2196
- Add a debug log when we get a block with an unknown parent. There was previously no logging around this case.
- Add a function to `BeaconState` to compute all proposers for an epoch without re-computing the active indices for each slot.
## Additional Info
- ~~Blocked on #2173~~
- ~~Blocked on #2179~~ That PR was wrapped into this PR.
- There's potentially some places where we could avoid computing the proposer indices in `per_block_processing` but I haven't done this here. These would be an optimization beyond the issue at hand (improving block propagation times) and I think this PR is already doing enough. We can come back for that later.
## TODO
- [x] Tidy, improve comments.
- [x] ~~Try avoid computing proposer index in `per_block_processing`?~~
## Issue Addressed
- Resolves#2064
## Proposed Changes
Adds a `ValidatorMonitor` struct which provides additional logging and Grafana metrics for specific validators.
Use `lighthouse bn --validator-monitor` to automatically enable monitoring for any validator that hits the [subnet subscription](https://ethereum.github.io/eth2.0-APIs/#/Validator/prepareBeaconCommitteeSubnet) HTTP API endpoint.
Also, use `lighthouse bn --validator-monitor-pubkeys` to supply a list of validators which will always be monitored.
See the new docs included in this PR for more info.
## TODO
- [x] Track validator balance, `slashed` status, etc.
- [x] ~~Register slashings in current epoch, not offense epoch~~
- [ ] Publish Grafana dashboard, update TODO link in docs
- [x] ~~#2130 is merged into this branch, resolve that~~
## Issue Addressed
Resolves#1434 (this is the last major feature in the standard spec. There are only a couple of places we may be off-spec due to recent spec changes or ongoing discussion)
Partly addresses #1669
## Proposed Changes
- remove the websocket server
- remove the `TeeEventHandler` and `NullEventHandler`
- add server sent events according to the eth2 API spec
## Additional Info
This is according to the currently unmerged PR here: https://github.com/ethereum/eth2.0-APIs/pull/117
Co-authored-by: realbigsean <seananderson33@gmail.com>
## Issue Addressed
Closes#1557
## Proposed Changes
Modify the pruning algorithm so that it mutates the head-tracker _before_ committing the database transaction to disk, and _only if_ all the heads to be removed are still present in the head-tracker (i.e. no concurrent mutations).
In the process of writing and testing this I also had to make a few other changes:
* Use internal mutability for all `BeaconChainHarness` functions (namely the RNG and the graffiti), in order to enable parallel calls (see testing section below).
* Disable logging in harness tests unless the `test_logger` feature is turned on
And chose to make some clean-ups:
* Delete the `NullMigrator`
* Remove type-based configuration for the migrator in favour of runtime config (simpler, less duplicated code)
* Use the non-blocking migrator unless the blocking migrator is required. In the store tests we need the blocking migrator because some tests make asserts about the state of the DB after the migration has run.
* Rename `validators_keypairs` -> `validator_keypairs` in the `BeaconChainHarness`
## Testing
To confirm that the fix worked, I wrote a test using [Hiatus](https://crates.io/crates/hiatus), which can be found here:
https://github.com/michaelsproul/lighthouse/tree/hiatus-issue-1557
That test can't be merged because it inserts random breakpoints everywhere, but if you check out that branch you can run the test with:
```
$ cd beacon_node/beacon_chain
$ cargo test --release --test parallel_tests --features test_logger
```
It should pass, and the log output should show:
```
WARN Pruning deferred because of a concurrent mutation, message: this is expected only very rarely!
```
## Additional Info
This is a backwards-compatible change with no impact on consensus.
The PR:
* Adds the ability to generate a crucial test scenario that isn't possible with `BeaconChainHarness` (i.e. two blocks occupying the same slot; previously forks necessitated skipping slots):
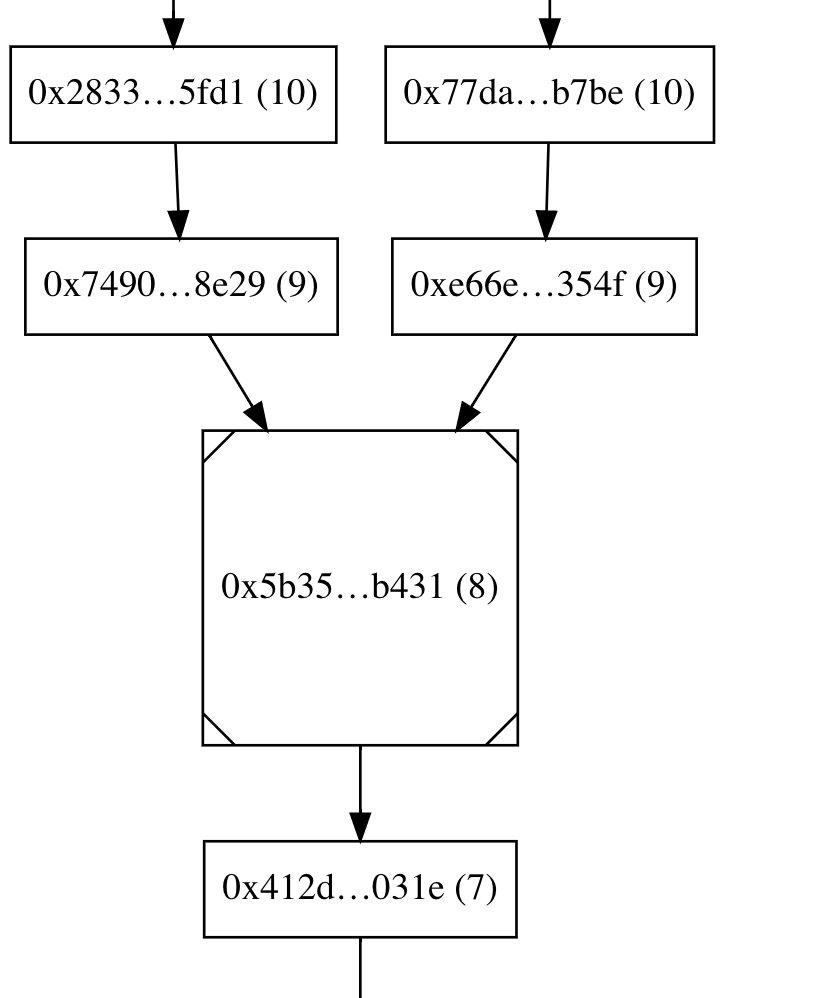
* New testing API: Instead of repeatedly calling add_block(), you generate a sorted `Vec<Slot>` and leave it up to the framework to generate blocks at those slots.
* Jumping backwards to an earlier epoch is a hard error, so that tests necessarily generate blocks in a epoch-by-epoch manner.
* Configures the test logger so that output is printed on the console in case a test fails. The logger also plays well with `--nocapture`, contrary to the existing testing framework
* Rewrites existing fork pruning tests to use the new API
* Adds a tests that triggers finalization at a non epoch boundary slot
* Renamed `BeaconChainYoke` to `BeaconChainTestingRig` because the former has been too confusing
* Fixed multiple tests (e.g. `block_production_different_shuffling_long`, `delete_blocks_and_states`, `shuffling_compatible_simple_fork`) that relied on a weird (and accidental) feature of the old `BeaconChainHarness` that attestations aren't produced for epochs earlier than the current one, thus masking potential bugs in test cases.
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Proposed Changes
To mitigate the impact of minority forks on RAM and disk usage, this change rejects blocks whose parent lies more than 320 slots (10 epochs, ~1 hour) in the past. The behaviour is configurable via `lighthouse bn --max-skip-slots N`, and can be turned off entirely using `--max-skip-slots none`.
Co-authored-by: Paul Hauner <paul@paulhauner.com>
* Process exits and slashings off the network
* Fix rest_api tests
* Add op verification tests
* Add tests for pruning of slashings in the op pool
* Address Paul's review comments
* Add PH & MS slot clock changes
* Account for genesis time
* Add progress on duties refactor
* Add simple is_aggregator bool to val subscription
* Start work on attestation_verification.rs
* Add progress on ObservedAttestations
* Progress with ObservedAttestations
* Fix tests
* Add observed attestations to the beacon chain
* Add attestation observation to processing code
* Add progress on attestation verification
* Add first draft of ObservedAttesters
* Add more tests
* Add observed attesters to beacon chain
* Add observers to attestation processing
* Add more attestation verification
* Create ObservedAggregators map
* Remove commented-out code
* Add observed aggregators into chain
* Add progress
* Finish adding features to attestation verification
* Ensure beacon chain compiles
* Link attn verification into chain
* Integrate new attn verification in chain
* Remove old attestation processing code
* Start trying to fix beacon_chain tests
* Split adding into pools into two functions
* Add aggregation to harness
* Get test harness working again
* Adjust the number of aggregators for test harness
* Fix edge-case in harness
* Integrate new attn processing in network
* Fix compile bug in validator_client
* Update validator API endpoints
* Fix aggreagation in test harness
* Fix enum thing
* Fix attestation observation bug:
* Patch failing API tests
* Start adding comments to attestation verification
* Remove unused attestation field
* Unify "is block known" logic
* Update comments
* Supress fork choice errors for network processing
* Add todos
* Tidy
* Add gossip attn tests
* Disallow test harness to produce old attns
* Comment out in-progress tests
* Partially address pruning tests
* Fix failing store test
* Add aggregate tests
* Add comments about which spec conditions we check
* Dont re-aggregate
* Split apart test harness attn production
* Fix compile error in network
* Make progress on commented-out test
* Fix skipping attestation test
* Add fork choice verification tests
* Tidy attn tests, remove dead code
* Remove some accidentally added code
* Fix clippy lint
* Rename test file
* Add block tests, add cheap block proposer check
* Rename block testing file
* Add observed_block_producers
* Tidy
* Switch around block signature verification
* Finish block testing
* Remove gossip from signature tests
* First pass of self review
* Fix deviation in spec
* Update test spec tags
* Start moving over to hashset
* Finish moving observed attesters to hashmap
* Move aggregation pool over to hashmap
* Make fc attn borrow again
* Fix rest_api compile error
* Fix missing comments
* Fix monster test
* Uncomment increasing slots test
* Address remaining comments
* Remove unsafe, use cfg test
* Remove cfg test flag
* Fix dodgy comment
* Ignore aggregates that are already known.
* Unify aggregator modulo logic
* Fix typo in logs
* Refactor validator subscription logic
* Avoid reproducing selection proof
* Skip HTTP call if no subscriptions
* Rename DutyAndState -> DutyAndProof
* Tidy logs
* Print root as dbg
* Fix compile errors in tests
* Fix compile error in test
* Address compiler warning
* Prune abandoned fork choice forks
* New approach to pruning
* Wrap some block hashes in a newtype pattern
For increased type safety.
* Add Graphviz chain dump emitter for debugging
* Fix broken test case
* Make prunes_abandoned_forks use real DiskStore
* Mark finalized blocks in the GraphViz output
* Refine debug stringification of Slot and Epoch
Before this commit: print!("{:?}", Slot(123)) == "Slot(\n123\n)".
After this commit: print!("{:?", Slot(123)) == "Slot(123)".
* Simplify build_block()
* Rewrite test case using more composable test primitives
* Working rewritten test case
* Tighten fork prunning test checks
* Add another pruning test case
* Bugfix: Finalized blocks weren't always properly detected
* Pruning: Add pruning_does_not_touch_blocks_prior_to_finalization test case
* Tighten pruning tests: check if heads are tracked properly
* Add a failing test case for a buggy scenario
* Change name of function to a more accurate one
* Fix failing test case
* Test case: Were skipped slots' states pruned?
* Style fix: Simplify dereferencing
* Tighten pruning tests: check if abandoned states are deleted
* Towards atomicity of db ops
* Correct typo
* Prune also skipped slots' states
* New logic for handling skipped states
* Make skipped slots test pass
* Post conflict resolution fixes
* Formatting fixes
* Tests passing
* Block hashes in Graphviz node labels
* Removed unused changes
* Fix bug with states having < SlotsPerHistoricalRoot roots
* Consolidate State/BlockRootsIterator for pruning
* Address review feedback
* Fix a bug in pruning tests
* Detach prune_abandoned_forks() from its object
* Move migrate.rs from store to beacon_chain
* Move forks pruning onto a background thread
* Bugfix: Heads weren't pruned when prune set contained only the head
* Rename: freeze_to_state() -> process_finalization()
* Eliminate redundant function parameter
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
{kind=link}
{kind=link}