* Changes to use required Endpoint
* Format
* fixed doppleganger service
* minor fix
* efficiency changes
* fixed tests
* remove commented line
---------
Co-authored-by: Jimmy Chen <jchen.tc@gmail.com>
* multiple broadcast flags
* rewrite with single --broadcast option
* satisfy cargo fmt
* shorten sync-committee-messages
* fix a doc comment and a test
* use strum
* Add broadcast test to simulator
* bring --disable-run-on-all flag back with deprecation notice
* Delete BN spec flag and VC beacon-node flag
* Remove warn
* slog
* add warn
* delete eth1-endpoint
* delete server from vc cli.rs
* delete server flag in config.rs
* delete delete-lockfiles in vc
* delete allow-unsynced flag in VC
* delete strict-fee-recipient in VC and warn log
* delete merge flag in bn (hidden)
* delete count-unrealized and count-unrealized-full in bn (hidden)
* delete http-disable-legacy-spec in bn (hidden)
* delete eth1-endpoint in lcli
* delete warn message lcli
* delete eth1-endpoints
* delete minify in slashing protection
* delete minify related
* Remove mut
* add back warn! log
* Indentation
* Delete count-unrealized
* Delete eth1-endpoints
* Delete eth1-endpoint test
* delete eth1-endpints test
* delete allow-unsynced test
* Add back lcli eth1-endpoint
---------
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Proposed Changes
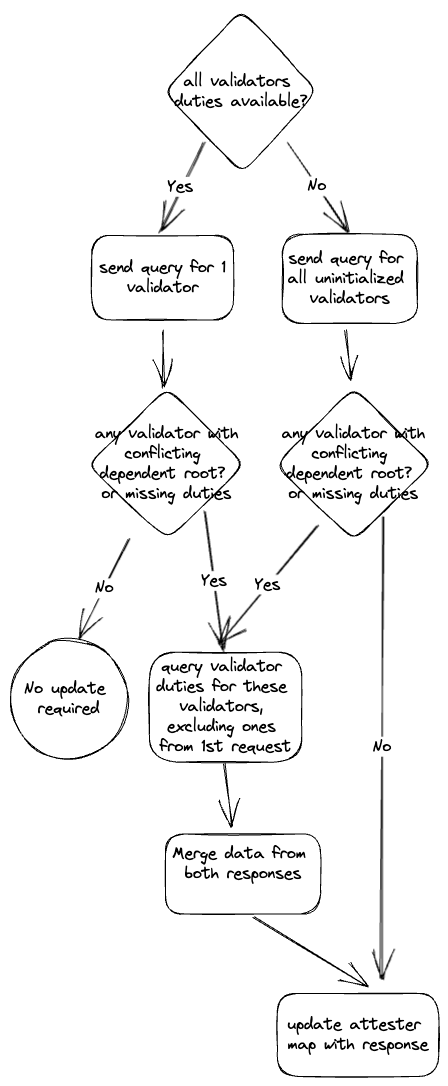
Instead of sending every attestation subscription every slot to every BN:
- Send subscriptions 32, 16, 8, 7, 6, 5, 4, 3 slots before they occur.
- Track whether each subscription is sent successfully and retry it in subsequent slots if necessary.
## Additional Info
- [x] Add unit tests for `SubscriptionSlots`.
- [x] Test on Holesky.
- [x] Based on #4774 for testing.
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/4712
## Proposed Changes
Exit aggregation step early if no validator is aggregator. This avoids an unnecessary request to the beacon node and more importantly fixes noisy errors if Lighthouse VC is used with other clients such as Lodestar and Prysm.
## Additional Info
Related issue https://github.com/ChainSafe/lodestar/issues/5553
## Issue Addressed
- Close#4596
## Proposed Changes
- Add `Filter::recover` to handle rejections specifically as 404 NOT FOUND
Please list or describe the changes introduced by this PR.
## Additional Info
Similar to PR #3836
## Proposed Changes
- only use LH types to avoid build issues
- use warp instead of axum for the server to avoid importing the dep
## Additional Info
- wondering if we can move the `execution_layer/test_utils` to its own crate and import it as a dev dependency
- this would be made easier by separating out our engine API types into their own crate so we can use them in the test crate
- or maybe we can look into using reth types for the engine api if they are in their own crate
Co-authored-by: realbigsean <seananderson33@gmail.com>
## Issue Addressed
#4635
## Proposed Changes
Wrap the `SignedVoluntaryExit` object in a `GenericResponse` container, adding an additional `data` layer, to ensure compliance with the key manager API specification.
The new response would look like this:
```json
{"data":{"message":{"epoch":"196868","validator_index":"505597"},"signature":"0xhexsig"}}
```
This is a backward incompatible change and will affect Siren as well.
## Issue Addressed
#4531
## Proposed Changes
add SSZ support to the following block production endpoints:
GET /eth/v2/validator/blocks/{slot}
GET /eth/v1/validator/blinded_blocks/{slot}
## Additional Info
i updated a few existing tests to use ssz instead of writing completely new tests
## Issue Addressed
On a new network a user might require importing validators before waiting until genesis has occurred.
## Proposed Changes
Starts the validator client http api before waiting for genesis
## Additional Info
cc @antondlr
## Issue Addressed
Closes#4473 (take 3)
## Proposed Changes
- Send a 202 status code by default for duplicate blocks, instead of 400. This conveys to the caller that the block was published, but makes no guarantees about its validity. Block relays can count this as a success or a failure as they wish.
- For users wanting finer-grained control over which status is returned for duplicates, a flag `--http-duplicate-block-status` can be used to adjust the behaviour. A 400 status can be supplied to restore the old (spec-compliant) behaviour, or a 200 status can be used to silence VCs that warn loudly for non-200 codes (e.g. Lighthouse prior to v4.4.0).
- Update the Lighthouse VC to gracefully handle success codes other than 200. The info message isn't the nicest thing to read, but it covers all bases and isn't a nasty `ERRO`/`CRIT` that will wake anyone up.
## Additional Info
I'm planning to raise a PR to `beacon-APIs` to specify that clients may return 202 for duplicate blocks. Really it would be nice to use some 2xx code that _isn't_ the same as the code for "published but invalid". I think unfortunately there aren't any suitable codes, and maybe the best fit is `409 CONFLICT`. Given that we need to fix this promptly for our release, I think using the 202 code temporarily with configuration strikes a nice compromise.
* remove protoc and token from network tests github action
* delete unused beacon chain methods
* downgrade writing blobs to store log
* reduce diff in block import logic
* remove some todo's and deneb built in network
* remove unnecessary error, actually use some added metrics
* remove some metrics, fix missing components on publish funcitonality
* fix status tests
* rename sidecar by root to blobs by root
* clean up some metrics
* remove unnecessary feature gate from attestation subnet tests, clean up blobs by range response code
* pawan's suggestion in `protocol_info`, peer score in matching up batch sync block and blobs
* fix range tests for deneb
* pub block and blob db cache behind the same mutex
* remove unused errs and an empty file
* move sidecar trait to new file
* move types from payload to eth2 crate
* update comment and add flag value name
* make function private again, remove allow unused
* use reth rlp for tx decoding
* fix compile after merge
* rename kzg commitments
* cargo fmt
* remove unused dep
* Update beacon_node/execution_layer/src/lib.rs
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
* Update beacon_node/beacon_processor/src/lib.rs
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
* pawan's suggestiong for vec capacity
* cargo fmt
* Revert "use reth rlp for tx decoding"
This reverts commit 5181837d81c66dcca4c960a85989ac30c7f806e2.
* remove reth rlp
---------
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
It seems `post_validator_duties_sync` is the only api which doesn't have its own metric in `duties_service`, this PR adds `metrics::VALIDATOR_DUTIES_SYNC_HTTP_POST` for completeness.
## Issue Addressed
Addresses #2557
## Proposed Changes
Adds the `lighthouse validator-manager` command, which provides:
- `lighthouse validator-manager create`
- Creates a `validators.json` file and a `deposits.json` (same format as https://github.com/ethereum/staking-deposit-cli)
- `lighthouse validator-manager import`
- Imports validators from a `validators.json` file to the VC via the HTTP API.
- `lighthouse validator-manager move`
- Moves validators from one VC to the other, utilizing only the VC API.
## Additional Info
In 98bcb947c I've reduced some VC `ERRO` and `CRIT` warnings to `WARN` or `DEBG` for the case where a pubkey is missing from the validator store. These were being triggered when we removed a validator but still had it in caches. It seems to me that `UnknownPubkey` will only happen in the case where we've removed a validator, so downgrading the logs is prudent. All the logs are `DEBG` apart from attestations and blocks which are `WARN`. I thought having *some* logging about this condition might help us down the track.
In 856cd7e37d I've made the VC delete the corresponding password file when it's deleting a keystore. This seemed like nice hygiene. Notably, it'll only delete that password file after it scans the validator definitions and finds that no other validator is also using that password file.
## Issue Addressed
#4386
## Proposed Changes
The original proposal described in the issue adds a new endpoint to support updating validator graffiti, but I realized we already have an endpoint that we use for updating various validator fields in memory and in the validator definitions file, so I think that would be the best place to add this to.
### API endpoint
`PATCH lighthouse/validators/{validator_pubkey}`
This endpoint updates the graffiti in both the [ validator definition file](https://lighthouse-book.sigmaprime.io/graffiti.html#2-setting-the-graffiti-in-the-validator_definitionsyml) and the in memory `InitializedValidators`. In the next block proposal, the new graffiti will be used.
Note that the [`--graffiti-file`](https://lighthouse-book.sigmaprime.io/graffiti.html#1-using-the---graffiti-file-flag-on-the-validator-client) flag has a priority over the validator definitions file, so if the caller attempts to update the graffiti while the `--graffiti-file` flag is present, the endpoint will return an error (Bad request 400).
## Tasks
- [x] Add graffiti update support to `PATCH lighthouse/validators/{validator_pubkey}`
- [x] Return error if user tries to update graffiti while the `--graffiti-flag` is set
- [x] Update Lighthouse book
## Issue Addressed
NA
## Proposed Changes
Adds the `--validator-registration-batch-size` flag to the VC to allow runtime configuration of the number of validators POSTed to the [`validator/register_validator`](https://ethereum.github.io/beacon-APIs/?urls.primaryName=dev#/Validator/registerValidator) endpoint.
There are builders (Agnostic and Eden) that are timing out with `regsiterValidator` requests with ~400 validators, even with a 9 second timeout. Exposing the batch size will help tune batch sizes to (hopefully) avoid this.
This PR should not change the behavior of Lighthouse when the new flag is not provided (i.e., the same default value is used).
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
Downgrade a `CRIT` to an `ERRO` when there's an `Irrecoverable` error whilst publishing a blinded block.
It's quite common for builders successfully broadcast a block to the network whilst failing to respond to the BN when it publishes a signed, blinded block. The VC is currently raising a `CRIT` when this happens and I think that's excessive.
These changes have the same intent as #4073. In that PR I only managed to remove the `CRIT`s in the BN but missed this one in the VC.
I've also tidied the log messages to:
- Give them all the same title (*"Error whilst producing block"*) to help with grepping.
- Include the `block_slot` so it's easy to look up the slot in an explorer and see if it was actually skipped.
## Additional Info
This PR should not change any logic beyond logging.
This PR adds the ability to read the Lighthouse logs from the HTTP API for both the BN and the VC.
This is done in such a way to as minimize any kind of performance hit by adding this feature.
The current design creates a tokio broadcast channel and mixes is into a form of slog drain that combines with our main global logger drain, only if the http api is enabled.
The drain gets the logs, checks the log level and drops them if they are below INFO. If they are INFO or higher, it sends them via a broadcast channel only if there are users subscribed to the HTTP API channel. If not, it drops the logs.
If there are more than one subscriber, the channel clones the log records and converts them to json in their independent HTTP API tasks.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
https://github.com/sigp/lighthouse/pull/4309#issuecomment-1556052261
## Proposed Changes
Log the `Connected to beacon node` message only if the node was previously offline. This avoids a regression in logging after #4295, whereby the `Connected to beacon node` message would be logged every slot.
The new reduced logging is _slightly different_ from what we had prior to my changes in #4295. The main difference is that we used to log the `Connected` message whenever a node was online and subject to a health check (for being unhealthy in some other way). I think the new behaviour is reasonable, as the `Connected` message isn't particularly helpful if the BN is unhealthy, and the specific reason for unhealthiness will be logged by the warnings for `is_compatible`/`is_synced`.
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/4291, part of #3613.
## Proposed Changes
- Implement the `el_offline` field on `/eth/v1/node/syncing`. We set `el_offline=true` if:
- The EL's internal status is `Offline` or `AuthFailed`, _or_
- The most recent call to `newPayload` resulted in an error (more on this in a moment).
- Use the `el_offline` field in the VC to mark nodes with offline ELs as _unsynced_. These nodes will still be used, but only after synced nodes.
- Overhaul the usage of `RequireSynced` so that `::No` is used almost everywhere. The `--allow-unsynced` flag was broken and had the opposite effect to intended, so it has been deprecated.
- Add tests for the EL being offline on the upcheck call, and being offline due to the newPayload check.
## Why track `newPayload` errors?
Tracking the EL's online/offline status is too coarse-grained to be useful in practice, because:
- If the EL is timing out to some calls, it's unlikely to timeout on the `upcheck` call, which is _just_ `eth_syncing`. Every failed call is followed by an upcheck [here](693886b941/beacon_node/execution_layer/src/engines.rs (L372-L380)), which would have the effect of masking the failure and keeping the status _online_.
- The `newPayload` call is the most likely to time out. It's the call in which ELs tend to do most of their work (often 1-2 seconds), with `forkchoiceUpdated` usually returning much faster (<50ms).
- If `newPayload` is failing consistently (e.g. timing out) then this is a good indication that either the node's EL is in trouble, or the network as a whole is. In the first case validator clients _should_ prefer other BNs if they have one available. In the second case, all of their BNs will likely report `el_offline` and they'll just have to proceed with trying to use them.
## Additional Changes
- Add utility method `ForkName::latest` which is quite convenient for test writing, but probably other things too.
- Delete some stale comments from when we used to support multiple execution nodes.
It is a well-known fact that IP addresses for beacon nodes used by specific validators can be de-anonymized. There is an assumed risk that a malicious user may attempt to DOS validators when producing blocks to prevent chain growth/liveness.
Although there are a number of ideas put forward to address this, there a few simple approaches we can take to mitigate this risk.
Currently, a Lighthouse user is able to set a number of beacon-nodes that their validator client can connect to. If one beacon node is taken offline, it can fallback to another. Different beacon nodes can use VPNs or rotate IPs in order to mask their IPs.
This PR provides an additional setup option which further mitigates attacks of this kind.
This PR introduces a CLI flag --proposer-only to the beacon node. Setting this flag will configure the beacon node to run with minimal peers and crucially will not subscribe to subnets or sync committees. Therefore nodes of this kind should not be identified as nodes connected to validators of any kind.
It also introduces a CLI flag --proposer-nodes to the validator client. Users can then provide a number of beacon nodes (which may or may not run the --proposer-only flag) that the Validator client will use for block production and propagation only. If these nodes fail, the validator client will fallback to the default list of beacon nodes.
Users are then able to set up a number of beacon nodes dedicated to block proposals (which are unlikely to be identified as validator nodes) and point their validator clients to produce blocks on these nodes and attest on other beacon nodes. An attack attempting to prevent liveness on the eth2 network would then need to preemptively find and attack the proposer nodes which is significantly more difficult than the default setup.
This is a follow on from: #3328
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
Co-authored-by: Paul Hauner <paul@paulhauner.com>
{kind=link}