## Issue Addressed
Fixes an issue that @paulhauner found with the v2.3.0 release candidate whereby the fork choice runs introduced by #3168 tripped over each other during sync:
```
May 24 23:06:40.542 WARN Error signalling fork choice waiter slot: 3884129, error: ForkChoiceSignalOutOfOrder { current: Slot(3884131), latest: Slot(3884129) }, service: beacon
```
This can occur because fork choice is called from the state advance _and_ the per-slot task. When one of these runs takes a long time it can end up finishing after a run from a later slot, tripping the error above. The problem is resolved by not running either of these fork choice calls during sync.
Additionally, these parallel fork choice runs were causing issues in the database:
```
May 24 07:49:05.098 WARN Found a chain that should already have been pruned, head_slot: 92925, head_block_root: 0xa76c7bf1b98e54ed4b0d8686efcfdf853484e6c2a4c67e91cbf19e5ad1f96b17, service: beacon
May 24 07:49:05.101 WARN Database migration failed error: HotColdDBError(FreezeSlotError { current_split_slot: Slot(92608), proposed_split_slot: Slot(92576) }), service: beacon
```
In this case, two fork choice calls triggering the finalization processing were being processed out of order due to differences in their processing time, causing the background migrator to try to advance finalization _backwards_ 😳. Removing the parallel fork choice runs from sync effectively addresses the issue, because these runs are most likely to have different finalized checkpoints (because of the speed at which fork choice advances during sync). In theory it's still possible to process updates out of order if any other fork choice runs end up completing out of order, but this should be much less common. Fixing out of order fork choice runs in general is difficult as it requires architectural changes like serialising fork choice updates through a single thread, or locking fork choice along with the head when it is mutated (https://github.com/sigp/lighthouse/pull/3175).
## Proposed Changes
* Don't run per-slot fork choice during sync (if head is older than 4 slots)
* Don't run state-advance fork choice during sync (if head is older than 4 slots)
* Check for monotonic finalization updates in the background migrator. This is a good defensive check to have, and I'm not sure why we didn't have it before (we may have had it and wrongly removed it).
## Proposed Changes
Reduce post-merge disk usage by not storing finalized execution payloads in Lighthouse's database.
⚠️ **This is achieved in a backwards-incompatible way for networks that have already merged** ⚠️. Kiln users and shadow fork enjoyers will be unable to downgrade after running the code from this PR. The upgrade migration may take several minutes to run, and can't be aborted after it begins.
The main changes are:
- New column in the database called `ExecPayload`, keyed by beacon block root.
- The `BeaconBlock` column now stores blinded blocks only.
- Lots of places that previously used full blocks now use blinded blocks, e.g. analytics APIs, block replay in the DB, etc.
- On finalization:
- `prune_abanonded_forks` deletes non-canonical payloads whilst deleting non-canonical blocks.
- `migrate_db` deletes finalized canonical payloads whilst deleting finalized states.
- Conversions between blinded and full blocks are implemented in a compositional way, duplicating some work from Sean's PR #3134.
- The execution layer has a new `get_payload_by_block_hash` method that reconstructs a payload using the EE's `eth_getBlockByHash` call.
- I've tested manually that it works on Kiln, using Geth and Nethermind.
- This isn't necessarily the most efficient method, and new engine APIs are being discussed to improve this: https://github.com/ethereum/execution-apis/pull/146.
- We're depending on the `ethers` master branch, due to lots of recent changes. We're also using a workaround for https://github.com/gakonst/ethers-rs/issues/1134.
- Payload reconstruction is used in the HTTP API via `BeaconChain::get_block`, which is now `async`. Due to the `async` fn, the `blocking_json` wrapper has been removed.
- Payload reconstruction is used in network RPC to serve blocks-by-{root,range} responses. Here the `async` adjustment is messier, although I think I've managed to come up with a reasonable compromise: the handlers take the `SendOnDrop` by value so that they can drop it on _task completion_ (after the `fn` returns). Still, this is introducing disk reads onto core executor threads, which may have a negative performance impact (thoughts appreciated).
## Additional Info
- [x] For performance it would be great to remove the cloning of full blocks when converting them to blinded blocks to write to disk. I'm going to experiment with a `put_block` API that takes the block by value, breaks it into a blinded block and a payload, stores the blinded block, and then re-assembles the full block for the caller.
- [x] We should measure the latency of blocks-by-root and blocks-by-range responses.
- [x] We should add integration tests that stress the payload reconstruction (basic tests done, issue for more extensive tests: https://github.com/sigp/lighthouse/issues/3159)
- [x] We should (manually) test the schema v9 migration from several prior versions, particularly as blocks have changed on disk and some migrations rely on being able to load blocks.
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
Successor to #2431
## Proposed Changes
* Add a `BlockReplayer` struct to abstract over the intricacies of calling `per_slot_processing` and `per_block_processing` while avoiding unnecessary tree hashing.
* Add a variant of the forwards state root iterator that does not require an `end_state`.
* Use the `BlockReplayer` when reconstructing states in the database. Use the efficient forwards iterator for frozen states.
* Refactor the iterators to remove `Arc<HotColdDB>` (this seems to be neater than making _everything_ an `Arc<HotColdDB>` as I did in #2431).
Supplying the state roots allow us to avoid building a tree hash cache at all when reconstructing historic states, which saves around 1 second flat (regardless of `slots-per-restore-point`). This is a small percentage of worst-case state load times with 200K validators and SPRP=2048 (~15s vs ~16s) but a significant speed-up for more frequent restore points: state loads with SPRP=32 should be now consistently <500ms instead of 1.5s (a ~3x speedup).
## Additional Info
Required by https://github.com/sigp/lighthouse/pull/2628
## Issue Addressed
Closes#1891Closes#1784
## Proposed Changes
Implement checkpoint sync for Lighthouse, enabling it to start from a weak subjectivity checkpoint.
## Additional Info
- [x] Return unavailable status for out-of-range blocks requested by peers (#2561)
- [x] Implement sync daemon for fetching historical blocks (#2561)
- [x] Verify chain hashes (either in `historical_blocks.rs` or the calling module)
- [x] Consistency check for initial block + state
- [x] Fetch the initial state and block from a beacon node HTTP endpoint
- [x] Don't crash fetching beacon states by slot from the API
- [x] Background service for state reconstruction, triggered by CLI flag or API call.
Considered out of scope for this PR:
- Drop the requirement to provide the `--checkpoint-block` (this would require some pretty heavy refactoring of block verification)
Co-authored-by: Diva M <divma@protonmail.com>
## Issue Addressed
Closes#2526
## Proposed Changes
If the head block fails to decode on start up, do two things:
1. Revert all blocks between the head and the most recent hard fork (to `fork_slot - 1`).
2. Reset fork choice so that it contains the new head, and all blocks back to the new head's finalized checkpoint.
## Additional Info
I tweaked some of the beacon chain test harness stuff in order to make it generic enough to test with a non-zero slot clock on start-up. In the process I consolidated all the various `new_` methods into a single generic one which will hopefully serve all future uses 🤞
## Proposed Changes
Implement the consensus changes necessary for the upcoming Altair hard fork.
## Additional Info
This is quite a heavy refactor, with pivotal types like the `BeaconState` and `BeaconBlock` changing from structs to enums. This ripples through the whole codebase with field accesses changing to methods, e.g. `state.slot` => `state.slot()`.
Co-authored-by: realbigsean <seananderson33@gmail.com>
## Issue Addressed
*Should* address #1917
## Proposed Changes
Stops the `BackgroupMigrator` rx channel from backing up with big `BeaconState` messages.
Looking at some logs from my Medalla node, we can see a discrepancy between the head finalized epoch and the migrator finalized epoch:
```
Nov 17 16:50:21.606 DEBG Head beacon block slot: 129214, root: 0xbc7a…0b99, finalized_epoch: 4033, finalized_root: 0xf930…6562, justified_epoch: 4035, justified_root: 0x206b…9321, service: beacon
Nov 17 16:50:21.626 DEBG Batch processed service: sync, processed_blocks: 43, last_block_slot: 129214, chain: 8274002112260436595, first_block_slot: 129153, batch_epoch: 4036
Nov 17 16:50:21.626 DEBG Chain advanced processing_target: 4036, new_start: 4036, previous_start: 4034, chain: 8274002112260436595, service: sync
Nov 17 16:50:22.162 DEBG Completed batch received awaiting_batches: 5, blocks: 47, epoch: 4048, chain: 8274002112260436595, service: sync
Nov 17 16:50:22.162 DEBG Requesting batch start_slot: 129601, end_slot: 129664, downloaded: 0, processed: 0, state: Downloading(16Uiu2HAmG3C3t1McaseReECjAF694tjVVjkDoneZEbxNhWm1nZaT, 0 blocks, 1273), epoch: 4050, chain: 8274002112260436595, service: sync
Nov 17 16:50:22.654 DEBG Database compaction complete service: beacon
Nov 17 16:50:22.655 INFO Starting database pruning new_finalized_epoch: 2193, old_finalized_epoch: 2192, service: beacon
```
I believe this indicates that the migrator rx has a backed-up queue of `MigrationNotification` items which each contain a `BeaconState`.
## TODO
- [x] Remove finalized state requirement for op-pool
## Proposed Changes
In an attempt to fix OOM issues and database consistency issues observed by some users after the introduction of compaction in v0.3.4, this PR makes the following changes:
* Run compaction less often: roughly every 1024 epochs, including after long periods of non-finality. I think the division check proposed by Paul is pretty solid, and ensures we don't miss any events where we should be compacting. LevelDB lacks an easy way to check the size of the DB, which would be another good trigger.
* Make it possible to disable the compaction on finalization using `--auto-compact-db=false`
* Make it possible to trigger a manual, single-threaded foreground compaction on start-up using `--compact-db`
* Downgrade the pruning log to `DEBUG`, as it's particularly noisy during sync
I would like to ship these changes to affected users ASAP, and will document them further in the Advanced Database section of the book if they prove effective.
## Issue Addressed
Closes#1866
## Proposed Changes
* Compact the database on finalization. This removes the deleted states from disk completely. Because it happens in the background migrator, it doesn't block other database operations while it runs. On my Medalla node it took about 1 minute and shrank the database from 90GB to 9GB.
* Fix an inefficiency in the pruning algorithm where it would always use the genesis checkpoint as the `old_finalized_checkpoint` when running for the first time after start-up. This would result in loading lots of states one-at-a-time back to genesis, and storing a lot of block roots in memory. The new code stores the old finalized checkpoint on disk and only uses genesis if no checkpoint is already stored. This makes it both backwards compatible _and_ forwards compatible -- no schema change required!
* Introduce two new `INFO` logs to indicate when pruning has started and completed. Users seem to want to know this information without enabling debug logs!
## Issue Addressed
Closes#800Closes#1713
## Proposed Changes
Implement the temporary state storage algorithm described in #800. Specifically:
* Add `DBColumn::BeaconStateTemporary`, for storing 0-length temporary marker values.
* Store intermediate states immediately as they are created, marked temporary. Delete the temporary flag if the block is processed successfully.
* Add a garbage collection process to delete leftover temporary states on start-up.
* Bump the database schema version to 2 so that a DB with temporary states can't accidentally be used with older versions of the software. The auto-migration is a no-op, but puts in place some infra that we can use for future migrations (e.g. #1784)
## Additional Info
There are two known race conditions, one potentially causing permanent faults (hopefully rare), and the other insignificant.
### Race 1: Permanent state marked temporary
EDIT: this has been fixed by the addition of a lock around the relevant critical section
There are 2 threads that are trying to store 2 different blocks that share some intermediate states (e.g. they both skip some slots from the current head). Consider this sequence of events:
1. Thread 1 checks if state `s` already exists, and seeing that it doesn't, prepares an atomic commit of `(s, s_temporary_flag)`.
2. Thread 2 does the same, but also gets as far as committing the state txn, finishing the processing of its block, and _deleting_ the temporary flag.
3. Thread 1 is (finally) scheduled again, and marks `s` as temporary with its transaction.
4.
a) The process is killed, or thread 1's block fails verification and the temp flag is not deleted. This is a permanent failure! Any attempt to load state `s` will fail... hope it isn't on the main chain! Alternatively (4b) happens...
b) Thread 1 finishes, and re-deletes the temporary flag. In this case the failure is transient, state `s` will disappear temporarily, but will come back once thread 1 finishes running.
I _hope_ that steps 1-3 only happen very rarely, and 4a even more rarely. It's hard to know
This once again begs the question of why we're using LevelDB (#483), when it clearly doesn't care about atomicity! A ham-fisted fix would be to wrap the hot and cold DBs in locks, which would bring us closer to how other DBs handle read-write transactions. E.g. [LMDB only allows one R/W transaction at a time](https://docs.rs/lmdb/0.8.0/lmdb/struct.Environment.html#method.begin_rw_txn).
### Race 2: Temporary state returned from `get_state`
I don't think this race really matters, but in `load_hot_state`, if another thread stores a state between when we call `load_state_temporary_flag` and when we call `load_hot_state_summary`, then we could end up returning that state even though it's only a temporary state. I can't think of any case where this would be relevant, and I suspect if it did come up, it would be safe/recoverable (having data is safer than _not_ having data).
This could be fixed by using a LevelDB read snapshot, but that would require substantial changes to how we read all our values, so I don't think it's worth it right now.
## Issue Addressed
Closes#1557
## Proposed Changes
Modify the pruning algorithm so that it mutates the head-tracker _before_ committing the database transaction to disk, and _only if_ all the heads to be removed are still present in the head-tracker (i.e. no concurrent mutations).
In the process of writing and testing this I also had to make a few other changes:
* Use internal mutability for all `BeaconChainHarness` functions (namely the RNG and the graffiti), in order to enable parallel calls (see testing section below).
* Disable logging in harness tests unless the `test_logger` feature is turned on
And chose to make some clean-ups:
* Delete the `NullMigrator`
* Remove type-based configuration for the migrator in favour of runtime config (simpler, less duplicated code)
* Use the non-blocking migrator unless the blocking migrator is required. In the store tests we need the blocking migrator because some tests make asserts about the state of the DB after the migration has run.
* Rename `validators_keypairs` -> `validator_keypairs` in the `BeaconChainHarness`
## Testing
To confirm that the fix worked, I wrote a test using [Hiatus](https://crates.io/crates/hiatus), which can be found here:
https://github.com/michaelsproul/lighthouse/tree/hiatus-issue-1557
That test can't be merged because it inserts random breakpoints everywhere, but if you check out that branch you can run the test with:
```
$ cd beacon_node/beacon_chain
$ cargo test --release --test parallel_tests --features test_logger
```
It should pass, and the log output should show:
```
WARN Pruning deferred because of a concurrent mutation, message: this is expected only very rarely!
```
## Additional Info
This is a backwards-compatible change with no impact on consensus.
The PR:
* Adds the ability to generate a crucial test scenario that isn't possible with `BeaconChainHarness` (i.e. two blocks occupying the same slot; previously forks necessitated skipping slots):
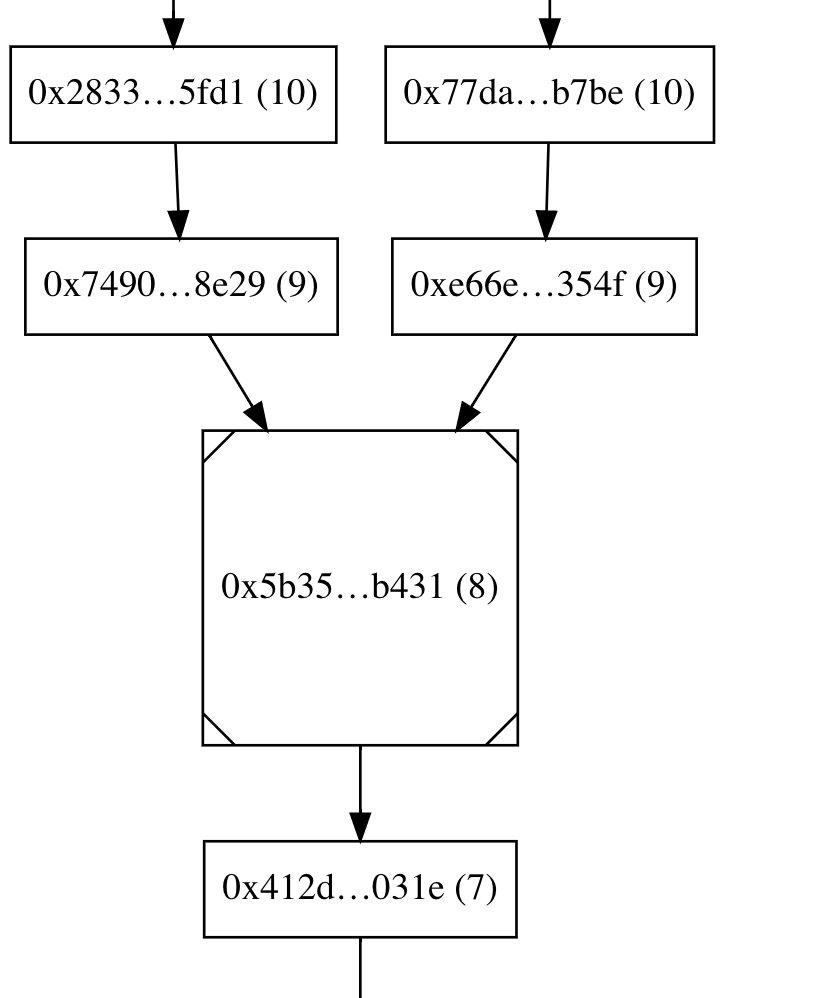
* New testing API: Instead of repeatedly calling add_block(), you generate a sorted `Vec<Slot>` and leave it up to the framework to generate blocks at those slots.
* Jumping backwards to an earlier epoch is a hard error, so that tests necessarily generate blocks in a epoch-by-epoch manner.
* Configures the test logger so that output is printed on the console in case a test fails. The logger also plays well with `--nocapture`, contrary to the existing testing framework
* Rewrites existing fork pruning tests to use the new API
* Adds a tests that triggers finalization at a non epoch boundary slot
* Renamed `BeaconChainYoke` to `BeaconChainTestingRig` because the former has been too confusing
* Fixed multiple tests (e.g. `block_production_different_shuffling_long`, `delete_blocks_and_states`, `shuffling_compatible_simple_fork`) that relied on a weird (and accidental) feature of the old `BeaconChainHarness` that attestations aren't produced for epochs earlier than the current one, thus masking potential bugs in test cases.
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Issue Addressed
Closes#1488
## Proposed Changes
* Prevent the pruning algorithm from over-eagerly deleting states at skipped slots when they are shared with the canonical chain.
* Add `debug` logging to the pruning algorithm so we have so better chance of debugging future issues from logs.
* Modify the handling of the "finalized state" in the beacon chain, so that it's always the state at the first slot of the finalized epoch (previously it was the state at the finalized block). This gives database pruning a clearer and cleaner view of things, and will marginally impact the pruning of the op pool, observed proposers, etc (in ways that are safe as far as I can tell).
* Remove duplicated `RevertedFinalizedEpoch` check from `after_finalization`
* Delete useless and unused `max_finality_distance`
* Add tests that exercise pruning with shared states at skip slots
* Delete unnecessary `block_strategy` argument from `add_blocks` and friends in the test harness (will likely conflict with #1380 slightly, sorry @adaszko -- but we can fix that)
* Bonus: add a `BeaconChain::with_head` method. I didn't end up needing it, but it turned out quite nice, so I figured we could keep it?
## Additional Info
Any users who have experienced pruning errors on Medalla will need to resync after upgrading to a release including this change. This should end unbounded `chain_db` growth! 🎉
* Layer do_atomically() abstractions properly
* Reduce allocs and DRY get_key_for_col()
* Parameterize HotColdDB with hot and cold item stores
* -impl Store for MemoryStore
* Replace Store uses with HotColdDB
* Ditch Store trait
* cargo fmt
* Style fix
* Readd missing dep that broke the build
* Remove redundant method
* Pull out a method out of a struct
* More precise db access abstractions
* Move fake trait method out of it
* cargo fmt
* Fix compilation error after refactoring
* Move another fake method out the Store trait
* Get rid of superfluous method
* Fix refactoring bug
* Rename: SimpleStoreItem -> StoreItem
* Get rid of the confusing DiskStore type alias
* Get rid of SimpleDiskStore type alias
* Correction: A method took both self and a ref to Self
* Improve error handling in block iteration
* Introduce atomic DB operations
* Fix race condition
An invariant was violated: For every block hash in head_tracker, that
block is accessible from the store.
* Address compiler warning
* Prune abandoned fork choice forks
* New approach to pruning
* Wrap some block hashes in a newtype pattern
For increased type safety.
* Add Graphviz chain dump emitter for debugging
* Fix broken test case
* Make prunes_abandoned_forks use real DiskStore
* Mark finalized blocks in the GraphViz output
* Refine debug stringification of Slot and Epoch
Before this commit: print!("{:?}", Slot(123)) == "Slot(\n123\n)".
After this commit: print!("{:?", Slot(123)) == "Slot(123)".
* Simplify build_block()
* Rewrite test case using more composable test primitives
* Working rewritten test case
* Tighten fork prunning test checks
* Add another pruning test case
* Bugfix: Finalized blocks weren't always properly detected
* Pruning: Add pruning_does_not_touch_blocks_prior_to_finalization test case
* Tighten pruning tests: check if heads are tracked properly
* Add a failing test case for a buggy scenario
* Change name of function to a more accurate one
* Fix failing test case
* Test case: Were skipped slots' states pruned?
* Style fix: Simplify dereferencing
* Tighten pruning tests: check if abandoned states are deleted
* Towards atomicity of db ops
* Correct typo
* Prune also skipped slots' states
* New logic for handling skipped states
* Make skipped slots test pass
* Post conflict resolution fixes
* Formatting fixes
* Tests passing
* Block hashes in Graphviz node labels
* Removed unused changes
* Fix bug with states having < SlotsPerHistoricalRoot roots
* Consolidate State/BlockRootsIterator for pruning
* Address review feedback
* Fix a bug in pruning tests
* Detach prune_abandoned_forks() from its object
* Move migrate.rs from store to beacon_chain
* Move forks pruning onto a background thread
* Bugfix: Heads weren't pruned when prune set contained only the head
* Rename: freeze_to_state() -> process_finalization()
* Eliminate redundant function parameter
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
{kind=link}