* - Update the fork choice `ProtoNode` to include `is_merge_complete`
- Add database migration for the persisted fork choice
* update tests
* Small cleanup
* lints
* store execution block hash in fork choice rather than bool
Added Execution Payload from Rayonism Fork
Updated new Containers to match Merge Spec
Updated BeaconBlockBody for Merge Spec
Completed updating BeaconState and BeaconBlockBody
Modified ExecutionPayload<T> to use Transaction<T>
Mostly Finished Changes for beacon-chain.md
Added some things for fork-choice.md
Update to match new fork-choice.md/fork.md changes
ran cargo fmt
Added Missing Pieces in eth2_libp2p for Merge
fix ef test
Various Changes to Conform Closer to Merge Spec
## Issue Addressed
Closes#1996
## Proposed Changes
Run a second `Logger` via `sloggers` which logs to a file in the background with:
- separate `debug-level` for background and terminal logging
- the ability to limit log size
- rotation through a customizable number of log files
- an option to compress old log files (`.gz` format)
Add the following new CLI flags:
- `--logfile-debug-level`: The debug level of the log files
- `--logfile-max-size`: The maximum size of each log file
- `--logfile-max-number`: The number of old log files to store
- `--logfile-compress`: Whether to compress old log files
By default background logging uses the `debug` log level and saves logfiles to:
- Beacon Node: `$HOME/.lighthouse/$network/beacon/logs/beacon.log`
- Validator Client: `$HOME/.lighthouse/$network/validators/logs/validator.log`
Or, when using the `--datadir` flag:
`$datadir/beacon/logs/beacon.log` and `$datadir/validators/logs/validator.log`
Once rotated, old logs are stored like so: `beacon.log.1`, `beacon.log.2` etc.
> Note: `beacon.log.1` is always newer than `beacon.log.2`.
## Additional Info
Currently the default value of `--logfile-max-size` is 200 (MB) and `--logfile-max-number` is 5.
This means that the maximum storage space that the logs will take up by default is 1.2GB.
(200MB x 5 from old log files + <200MB the current logfile being written to)
Happy to adjust these default values to whatever people think is appropriate.
It's also worth noting that when logging to a file, we lose our custom `slog` formatting. This means the logfile logs look like this:
```
Oct 27 16:02:50.305 INFO Lighthouse started, version: Lighthouse/v2.0.1-8edd9d4+, module: lighthouse:413
Oct 27 16:02:50.305 INFO Configured for network, name: prater, module: lighthouse:414
```
## Proposed Changes
* Add the `Eth-Consensus-Version` header to the HTTP API for the block and state endpoints. This is part of the v2.1.0 API that was recently released: https://github.com/ethereum/beacon-APIs/pull/170
* Add tests for the above. I refactored the `eth2` crate's helper functions to make this more straight-forward, and introduced some new mixin traits that I think greatly improve readability and flexibility.
* Add a new `map_with_fork!` macro which is useful for decoding a superstruct type without naming all its variants. It is now used for SSZ-decoding `BeaconBlock` and `BeaconState`, and for JSON-decoding `SignedBeaconBlock` in the API.
## Additional Info
The `map_with_fork!` changes will conflict with the Merge changes, but when resolving the conflict the changes from this branch should be preferred (it is no longer necessary to enumerate every fork). The merge fork _will_ need to be added to `map_fork_name_with`.
## Issue Addressed
When compiling with Rust 1.56.0 the compiler generates 3 instances of this warning:
```
warning: trailing semicolon in macro used in expression position
--> common/eth2_network_config/src/lib.rs:181:24
|
181 | })?;
| ^
...
195 | let deposit_contract_deploy_block = load_from_file!(DEPLOY_BLOCK_FILE);
| ---------------------------------- in this macro invocation
|
= note: `#[warn(semicolon_in_expressions_from_macros)]` on by default
= warning: this was previously accepted by the compiler but is being phased out; it will become a hard error in a future release!
= note: for more information, see issue #79813 <https://github.com/rust-lang/rust/issues/79813>
= note: this warning originates in the macro `load_from_file` (in Nightly builds, run with -Z macro-backtrace for more info)
```
This warning is completely harmless, but will be visible to users compiling Lighthouse v2.0.1 (or earlier) with Rust 1.56.0 (to be released October 21st). It is **completely safe** to ignore this warning, it's just a superficial change to Rust's syntax.
## Proposed Changes
This PR removes the semi-colon as recommended, and fixes the new Clippy lints from 1.56.0
## Issue Addressed
NA
## Proposed Changes
This PR is near-identical to https://github.com/sigp/lighthouse/pull/2652, however it is to be merged into `unstable` instead of `merge-f2f`. Please see that PR for reasoning.
I'm making this duplicate PR to merge to `unstable` in an effort to shrink the diff between `unstable` and `merge-f2f` by doing smaller, lead-up PRs.
## Additional Info
NA
## Issue Addressed
This PR addresses an issue found by @YorickDowne during testing of v2.0.0-rc.0.
Due to a lack of atomic database writes on checkpoint sync start-up, it was possible for the database to get into an inconsistent state from which it couldn't recover without `--purge-db`. The core of the issue was that the store's anchor info was being stored _before_ the `PersistedBeaconChain`. If a crash occured so that anchor info was stored but _not_ the `PersistedBeaconChain`, then on restart Lighthouse would think the database was unitialized and attempt to compare-and-swap a `None` value, but would actually find the stale info from the previous run.
## Proposed Changes
The issue is fixed by writing the anchor info, the split point, and the `PersistedBeaconChain` atomically on start-up. Some type-hinting ugliness was required, which could possibly be cleaned up in future refactors.
## Issue Addressed
NA
## Proposed Changes
Implements the "union" type from the SSZ spec for `ssz`, `ssz_derive`, `tree_hash` and `tree_hash_derive` so it may be derived for `enums`:
https://github.com/ethereum/consensus-specs/blob/v1.1.0-beta.3/ssz/simple-serialize.md#union
The union type is required for the merge, since the `Transaction` type is defined as a single-variant union `Union[OpaqueTransaction]`.
### Crate Updates
This PR will (hopefully) cause CI to publish new versions for the following crates:
- `eth2_ssz_derive`: `0.2.1` -> `0.3.0`
- `eth2_ssz`: `0.3.0` -> `0.4.0`
- `eth2_ssz_types`: `0.2.0` -> `0.2.1`
- `tree_hash`: `0.3.0` -> `0.4.0`
- `tree_hash_derive`: `0.3.0` -> `0.4.0`
These these crates depend on each other, I've had to add a workspace-level `[patch]` for these crates. A follow-up PR will need to remove this patch, ones the new versions are published.
### Union Behaviors
We already had SSZ `Encode` and `TreeHash` derive for enums, however it just did a "transparent" pass-through of the inner value. Since the "union" decoding from the spec is in conflict with the transparent method, I've required that all `enum` have exactly one of the following enum-level attributes:
#### SSZ
- `#[ssz(enum_behaviour = "union")]`
- matches the spec used for the merge
- `#[ssz(enum_behaviour = "transparent")]`
- maintains existing functionality
- not supported for `Decode` (never was)
#### TreeHash
- `#[tree_hash(enum_behaviour = "union")]`
- matches the spec used for the merge
- `#[tree_hash(enum_behaviour = "transparent")]`
- maintains existing functionality
This means that we can maintain the existing transparent behaviour, but all existing users will get a compile-time error until they explicitly opt-in to being transparent.
### Legacy Option Encoding
Before this PR, we already had a union-esque encoding for `Option<T>`. However, this was with the *old* SSZ spec where the union selector was 4 bytes. During merge specification, the spec was changed to use 1 byte for the selector.
Whilst the 4-byte `Option` encoding was never used in the spec, we used it in our database. Writing a migrate script for all occurrences of `Option` in the database would be painful, especially since it's used in the `CommitteeCache`. To avoid the migrate script, I added a serde-esque `#[ssz(with = "module")]` field-level attribute to `ssz_derive` so that we can opt into the 4-byte encoding on a field-by-field basis.
The `ssz::legacy::four_byte_impl!` macro allows a one-liner to define the module required for the `#[ssz(with = "module")]` for some `Option<T> where T: Encode + Decode`.
Notably, **I have removed `Encode` and `Decode` impls for `Option`**. I've done this to force a break on downstream users. Like I mentioned, `Option` isn't used in the spec so I don't think it'll be *that* annoying. I think it's nicer than quietly having two different union implementations or quietly breaking the existing `Option` impl.
### Crate Publish Ordering
I've modified the order in which CI publishes crates to ensure that we don't publish a crate without ensuring we already published a crate that it depends upon.
## TODO
- [ ] Queue a follow-up `[patch]`-removing PR.
## Issue Addressed
Closes#1891Closes#1784
## Proposed Changes
Implement checkpoint sync for Lighthouse, enabling it to start from a weak subjectivity checkpoint.
## Additional Info
- [x] Return unavailable status for out-of-range blocks requested by peers (#2561)
- [x] Implement sync daemon for fetching historical blocks (#2561)
- [x] Verify chain hashes (either in `historical_blocks.rs` or the calling module)
- [x] Consistency check for initial block + state
- [x] Fetch the initial state and block from a beacon node HTTP endpoint
- [x] Don't crash fetching beacon states by slot from the API
- [x] Background service for state reconstruction, triggered by CLI flag or API call.
Considered out of scope for this PR:
- Drop the requirement to provide the `--checkpoint-block` (this would require some pretty heavy refactoring of block verification)
Co-authored-by: Diva M <divma@protonmail.com>
## Proposed Changes
Cache the total active balance for the current epoch in the `BeaconState`. Computing this value takes around 1ms, and this was negatively impacting block processing times on Prater, particularly when reconstructing states.
With a large number of attestations in each block, I saw the `process_attestations` function taking 150ms, which means that reconstructing hot states can take up to 4.65s (31 * 150ms), and reconstructing freezer states can take up to 307s (2047 * 150ms).
I opted to add the cache to the beacon state rather than computing the total active balance at the start of state processing and threading it through. Although this would be simpler in a way, it would waste time, particularly during block replay, as the total active balance doesn't change for the duration of an epoch. So we save ~32ms for hot states, and up to 8.1s for freezer states (using `--slots-per-restore-point 8192`).
## Issue Addressed
Related to: #2259
Made an attempt at all the necessary updates here to publish the crates to crates.io. I incremented the minor versions on all the crates that have been previously published. We still might run into some issues as we try to publish because I'm not able to test this out but I think it's a good starting point.
## Proposed Changes
- Add description and license to `ssz_types` and `serde_util`
- rename `serde_util` to `eth2_serde_util`
- increment minor versions
- remove path dependencies
- remove patch dependencies
## Additional Info
Crates published:
- [x] `tree_hash` -- need to publish `tree_hash_derive` and `eth2_hashing` first
- [x] `eth2_ssz_types` -- need to publish `eth2_serde_util` first
- [x] `tree_hash_derive`
- [x] `eth2_ssz`
- [x] `eth2_ssz_derive`
- [x] `eth2_serde_util`
- [x] `eth2_hashing`
Co-authored-by: realbigsean <seananderson33@gmail.com>
## Issue Addressed
Closes#2526
## Proposed Changes
If the head block fails to decode on start up, do two things:
1. Revert all blocks between the head and the most recent hard fork (to `fork_slot - 1`).
2. Reset fork choice so that it contains the new head, and all blocks back to the new head's finalized checkpoint.
## Additional Info
I tweaked some of the beacon chain test harness stuff in order to make it generic enough to test with a non-zero slot clock on start-up. In the process I consolidated all the various `new_` methods into a single generic one which will hopefully serve all future uses 🤞
## Issue Addressed
N/A
## Proposed Changes
- Removing a bunch of unnecessary references
- Updated `Error::VariantError` to `Error::Variant`
- There were additional enum variant lints that I ignored, because I thought our variant names were fine
- removed `MonitoredValidator`'s `pubkey` field, because I couldn't find it used anywhere. It looks like we just use the string version of the pubkey (the `id` field) if there is no index
## Additional Info
Co-authored-by: realbigsean <seananderson33@gmail.com>
## Issue Addressed
Closes#2245
## Proposed Changes
Replace all calls to `RwLock::read` in the `store` crate with `RwLock::read_recursive`.
## Additional Info
* Unfortunately we can't run the deadlock detector on CI because it's pinned to an old Rust 1.51.0 nightly which cannot compile Lighthouse (one of our deps uses `ptr::addr_of!` which is too new). A fun side-project at some point might be to update the deadlock detector.
* The reason I think we haven't seen this deadlock (at all?) in practice is that _writes_ to the database's split point are quite infrequent, and a concurrent write is required to trigger the deadlock. The split point is only written when finalization advances, which is once per epoch (every ~6 minutes), and state reads are also quite sporadic. Perhaps we've just been incredibly lucky, or there's something about the timing of state reads vs database migration that protects us.
* I wrote a few small programs to demo the deadlock, and the effectiveness of the `read_recursive` fix: https://github.com/michaelsproul/relock_deadlock_mvp
* [The docs for `read_recursive`](https://docs.rs/lock_api/0.4.2/lock_api/struct.RwLock.html#method.read_recursive) warn of starvation for writers. I think in order for starvation to occur the database would have to be spammed with so many state reads that it's unable to ever clear them all and find time for a write, in which case migration of states to the freezer would cease. If an attack could be performed to trigger this starvation then it would likely trigger a deadlock in the current code, and I think ceasing migration is preferable to deadlocking in this extreme situation. In practice neither should occur due to protection from spammy peers at the network layer. Nevertheless, it would be prudent to run this change on the testnet nodes to check that it doesn't cause accidental starvation.
## Proposed Changes
Implement the consensus changes necessary for the upcoming Altair hard fork.
## Additional Info
This is quite a heavy refactor, with pivotal types like the `BeaconState` and `BeaconBlock` changing from structs to enums. This ripples through the whole codebase with field accesses changing to methods, e.g. `state.slot` => `state.slot()`.
Co-authored-by: realbigsean <seananderson33@gmail.com>
## Issue Addressed
#2377
## Proposed Changes
Implement the same code used for block root lookups (from #2376) to state root lookups in order to improve performance and reduce associated memory spikes (e.g. from certain HTTP API requests).
## Additional Changes
- Tests using `rev_iter_state_roots` and `rev_iter_block_roots` have been refactored to use their `forwards` versions instead.
- The `rev_iter_state_roots` and `rev_iter_block_roots` functions are now unused and have been removed.
- The `state_at_slot` function has been changed to use the `forwards` iterator.
## Additional Info
- Some tests still need to be refactored to use their `forwards_iter` versions. These tests start their iteration from a specific beacon state and thus use the `rev_iter_state_roots_from` and `rev_iter_block_roots_from` functions. If they can be refactored, those functions can also be removed.
## Issue Addressed
`make lint` failing on rust 1.53.0.
## Proposed Changes
1.53.0 updates
## Additional Info
I haven't figure out why yet, we were now hitting the recursion limit in a few crates. So I had to add `#![recursion_limit = "256"]` in a few places
Co-authored-by: realbigsean <seananderson33@gmail.com>
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Issue Addressed
NA
## Proposed Changes
Return a very specific error when at attestation reads shuffling from a frozen `BeaconState`. Previously, this was returning `MissingBeaconState` which indicates a much more serious issue.
## Additional Info
Since `get_inconsistent_state_for_attestation_verification_only` is only called once in `BeaconChain::with_committee_cache`, it is quite easy to reason about the impact of this change.
## Issue Addressed
NA
## Primary Change
When investigating memory usage, I noticed that retrieving a block from an early slot (e.g., slot 900) would cause a sharp increase in the memory footprint (from 400mb to 800mb+) which seemed to be ever-lasting.
After some investigation, I found that the reverse iteration from the head back to that slot was the likely culprit. To counter this, I've switched the `BeaconChain::block_root_at_slot` to use the forwards iterator, instead of the reverse one.
I also noticed that the networking stack is using `BeaconChain::root_at_slot` to check if a peer is relevant (`check_peer_relevance`). Perhaps the steep, seemingly-random-but-consistent increases in memory usage are caused by the use of this function.
Using the forwards iterator with the HTTP API alleviated the sharp increases in memory usage. It also made the response much faster (before it felt like to took 1-2s, now it feels instant).
## Additional Changes
In the process I also noticed that we have two functions for getting block roots:
- `BeaconChain::block_root_at_slot`: returns `None` for a skip slot.
- `BeaconChain::root_at_slot`: returns the previous root for a skip slot.
I unified these two functions into `block_root_at_slot` and added the `WhenSlotSkipped` enum. Now, the caller must be explicit about the skip-slot behaviour when requesting a root.
Additionally, I replaced `vec![]` with `Vec::with_capacity` in `store::chunked_vector::range_query`. I stumbled across this whilst debugging and made this modification to see what effect it would have (not much). It seems like a decent change to keep around, but I'm not concerned either way.
Also, `BeaconChain::get_ancestor_block_root` is unused, so I got rid of it 🗑️.
## Additional Info
I haven't also done the same for state roots here. Whilst it's possible and a good idea, it's more work since the fwds iterators are presently block-roots-specific.
Whilst there's a few places a reverse iteration of state roots could be triggered (e.g., attestation production, HTTP API), they're no where near as common as the `check_peer_relevance` call. As such, I think we should get this PR merged first, then come back for the state root iters. I made an issue here https://github.com/sigp/lighthouse/issues/2377.
## Issue Addressed
Closes#2274
## Proposed Changes
* Modify the `YamlConfig` to collect unknown fields into an `extra_fields` map, instead of failing hard.
* Log a debug message if there are extra fields returned to the VC from one of its BNs.
This restores Lighthouse's compatibility with Teku beacon nodes (and therefore Infura)
## Issue Addressed
Closes#2052
## Proposed Changes
- Refactor the attester/proposer duties endpoints in the BN
- Performance improvements
- Fixes some potential inconsistencies with the dependent root fields.
- Removes `http_api::beacon_proposer_cache` and just uses the one on the `BeaconChain` instead.
- Move the code for the proposer/attester duties endpoints into separate files, for readability.
- Refactor the `DutiesService` in the VC
- Required to reduce the delay on broadcasting new blocks.
- Gets rid of the `ValidatorDuty` shim struct that came about when we adopted the standard API.
- Separate block/attestation duty tasks so that they don't block each other when one is slow.
- In the VC, use `PublicKeyBytes` to represent validators instead of `PublicKey`. `PublicKey` is a legit crypto object whilst `PublicKeyBytes` is just a byte-array, it's much faster to clone/hash `PublicKeyBytes` and this change has had a significant impact on runtimes.
- Unfortunately this has created lots of dust changes.
- In the BN, store `PublicKeyBytes` in the `beacon_proposer_cache` and allow access to them. The HTTP API always sends `PublicKeyBytes` over the wire and the conversion from `PublicKey` -> `PublickeyBytes` is non-trivial, especially when queries have 100s/1000s of validators (like Pyrmont).
- Add the `state_processing::state_advance` mod which dedups a lot of the "apply `n` skip slots to the state" code.
- This also fixes a bug with some functions which were failing to include a state root as per [this comment](072695284f/consensus/state_processing/src/state_advance.rs (L69-L74)). I couldn't find any instance of this bug that resulted in anything more severe than keying a shuffling cache by the wrong block root.
- Swap the VC block service to use `mpsc` from `tokio` instead of `futures`. This is consistent with the rest of the code base.
~~This PR *reduces* the size of the codebase 🎉~~ It *used* to reduce the size of the code base before I added more comments.
## Observations on Prymont
- Proposer duties times down from peaks of 450ms to consistent <1ms.
- Current epoch attester duties times down from >1s peaks to a consistent 20-30ms.
- Block production down from +600ms to 100-200ms.
## Additional Info
- ~~Blocked on #2241~~
- ~~Blocked on #2234~~
## TODO
- [x] ~~Refactor this into some smaller PRs?~~ Leaving this as-is for now.
- [x] Address `per_slot_processing` roots.
- [x] Investigate slow next epoch times. Not getting added to cache on block processing?
- [x] Consider [this](072695284f/beacon_node/store/src/hot_cold_store.rs (L811-L812)) in the scenario of replacing the state roots
Co-authored-by: pawan <pawandhananjay@gmail.com>
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Issue Addressed
Closes#1787
## Proposed Changes
* Abstract the `ValidatorPubkeyCache` over a "backing" which is either a file (legacy), or the database.
* Implement a migration from schema v2 to schema v3, whereby the contents of the cache file are copied to the DB, and then the file is deleted. The next release to include this change must be a minor version bump, and we will need to warn users of the inability to downgrade (this is our first DB schema change since mainnet genesis).
* Move the schema migration code from the `store` crate into the `beacon_chain` crate so that it can access the datadir and the `ValidatorPubkeyCache`, etc. It gets injected back into the `store` via a closure (similar to what we do in fork choice).
## Issue Addressed
`test_dht_persistence` failing
## Proposed Changes
Bind `NetworkService::start` to an underscore prefixed variable rather than `_`. `_` was causing it to be dropped immediately
This was failing 5/100 times before this update, but I haven't been able to get it to fail after updating it
Co-authored-by: realbigsean <seananderson33@gmail.com>
## Issue Addressed
NA
## Proposed Changes
Updates out of date dependencies.
## Additional Info
See also https://github.com/sigp/lighthouse/issues/1712 for a list of dependencies that are still out of date and the resasons.
## Proposed Changes
A user on Discord reported build issues when trying to compile Lighthouse checked out to a path with spaces in it. I've fixed the issue upstream in `leveldb-sys` (https://github.com/skade/leveldb-sys/pull/22), but rather than waiting for a new release of the `leveldb` crate, we can also work around the issue by disabling Snappy in LevelDB, which we weren't using anyway.
This may also have the side-effect of slightly improving compilation times, as LevelDB+Snappy was found to be a substantial contributor to build time (although I'm not sure how much was LevelDB and how much was Snappy).
This is an implementation of a slasher that lives inside the BN and can be enabled via `lighthouse bn --slasher`.
Features included in this PR:
- [x] Detection of attester slashing conditions (double votes, surrounds existing, surrounded by existing)
- [x] Integration into Lighthouse's attestation verification flow
- [x] Detection of proposer slashing conditions
- [x] Extraction of attestations from blocks as they are verified
- [x] Compression of chunks
- [x] Configurable history length
- [x] Pruning of old attestations and blocks
- [x] More tests
Future work:
* Focus on a slice of history separate from the most recent N epochs (e.g. epochs `current - K` to `current - M`)
* Run out-of-process
* Ingest attestations from the chain without a resync
Design notes are here https://hackmd.io/@sproul/HJSEklmPL
## Proposed Changes
In an attempt to fix OOM issues and database consistency issues observed by some users after the introduction of compaction in v0.3.4, this PR makes the following changes:
* Run compaction less often: roughly every 1024 epochs, including after long periods of non-finality. I think the division check proposed by Paul is pretty solid, and ensures we don't miss any events where we should be compacting. LevelDB lacks an easy way to check the size of the DB, which would be another good trigger.
* Make it possible to disable the compaction on finalization using `--auto-compact-db=false`
* Make it possible to trigger a manual, single-threaded foreground compaction on start-up using `--compact-db`
* Downgrade the pruning log to `DEBUG`, as it's particularly noisy during sync
I would like to ship these changes to affected users ASAP, and will document them further in the Advanced Database section of the book if they prove effective.
## Issue Addressed
Closes#1866
## Proposed Changes
* Compact the database on finalization. This removes the deleted states from disk completely. Because it happens in the background migrator, it doesn't block other database operations while it runs. On my Medalla node it took about 1 minute and shrank the database from 90GB to 9GB.
* Fix an inefficiency in the pruning algorithm where it would always use the genesis checkpoint as the `old_finalized_checkpoint` when running for the first time after start-up. This would result in loading lots of states one-at-a-time back to genesis, and storing a lot of block roots in memory. The new code stores the old finalized checkpoint on disk and only uses genesis if no checkpoint is already stored. This makes it both backwards compatible _and_ forwards compatible -- no schema change required!
* Introduce two new `INFO` logs to indicate when pruning has started and completed. Users seem to want to know this information without enabling debug logs!
## Issue Addressed
Closes#800Closes#1713
## Proposed Changes
Implement the temporary state storage algorithm described in #800. Specifically:
* Add `DBColumn::BeaconStateTemporary`, for storing 0-length temporary marker values.
* Store intermediate states immediately as they are created, marked temporary. Delete the temporary flag if the block is processed successfully.
* Add a garbage collection process to delete leftover temporary states on start-up.
* Bump the database schema version to 2 so that a DB with temporary states can't accidentally be used with older versions of the software. The auto-migration is a no-op, but puts in place some infra that we can use for future migrations (e.g. #1784)
## Additional Info
There are two known race conditions, one potentially causing permanent faults (hopefully rare), and the other insignificant.
### Race 1: Permanent state marked temporary
EDIT: this has been fixed by the addition of a lock around the relevant critical section
There are 2 threads that are trying to store 2 different blocks that share some intermediate states (e.g. they both skip some slots from the current head). Consider this sequence of events:
1. Thread 1 checks if state `s` already exists, and seeing that it doesn't, prepares an atomic commit of `(s, s_temporary_flag)`.
2. Thread 2 does the same, but also gets as far as committing the state txn, finishing the processing of its block, and _deleting_ the temporary flag.
3. Thread 1 is (finally) scheduled again, and marks `s` as temporary with its transaction.
4.
a) The process is killed, or thread 1's block fails verification and the temp flag is not deleted. This is a permanent failure! Any attempt to load state `s` will fail... hope it isn't on the main chain! Alternatively (4b) happens...
b) Thread 1 finishes, and re-deletes the temporary flag. In this case the failure is transient, state `s` will disappear temporarily, but will come back once thread 1 finishes running.
I _hope_ that steps 1-3 only happen very rarely, and 4a even more rarely. It's hard to know
This once again begs the question of why we're using LevelDB (#483), when it clearly doesn't care about atomicity! A ham-fisted fix would be to wrap the hot and cold DBs in locks, which would bring us closer to how other DBs handle read-write transactions. E.g. [LMDB only allows one R/W transaction at a time](https://docs.rs/lmdb/0.8.0/lmdb/struct.Environment.html#method.begin_rw_txn).
### Race 2: Temporary state returned from `get_state`
I don't think this race really matters, but in `load_hot_state`, if another thread stores a state between when we call `load_state_temporary_flag` and when we call `load_hot_state_summary`, then we could end up returning that state even though it's only a temporary state. I can't think of any case where this would be relevant, and I suspect if it did come up, it would be safe/recoverable (having data is safer than _not_ having data).
This could be fixed by using a LevelDB read snapshot, but that would require substantial changes to how we read all our values, so I don't think it's worth it right now.
## Issue Addressed
Closes#1557
## Proposed Changes
Modify the pruning algorithm so that it mutates the head-tracker _before_ committing the database transaction to disk, and _only if_ all the heads to be removed are still present in the head-tracker (i.e. no concurrent mutations).
In the process of writing and testing this I also had to make a few other changes:
* Use internal mutability for all `BeaconChainHarness` functions (namely the RNG and the graffiti), in order to enable parallel calls (see testing section below).
* Disable logging in harness tests unless the `test_logger` feature is turned on
And chose to make some clean-ups:
* Delete the `NullMigrator`
* Remove type-based configuration for the migrator in favour of runtime config (simpler, less duplicated code)
* Use the non-blocking migrator unless the blocking migrator is required. In the store tests we need the blocking migrator because some tests make asserts about the state of the DB after the migration has run.
* Rename `validators_keypairs` -> `validator_keypairs` in the `BeaconChainHarness`
## Testing
To confirm that the fix worked, I wrote a test using [Hiatus](https://crates.io/crates/hiatus), which can be found here:
https://github.com/michaelsproul/lighthouse/tree/hiatus-issue-1557
That test can't be merged because it inserts random breakpoints everywhere, but if you check out that branch you can run the test with:
```
$ cd beacon_node/beacon_chain
$ cargo test --release --test parallel_tests --features test_logger
```
It should pass, and the log output should show:
```
WARN Pruning deferred because of a concurrent mutation, message: this is expected only very rarely!
```
## Additional Info
This is a backwards-compatible change with no impact on consensus.
## Issue Addressed
- Resolves#1706
## Proposed Changes
Updates dependencies across the workspace. Any crate that was not able to be brought to the latest version is listed in #1712.
## Additional Info
NA
## Issue Addressed
Closes#673
## Proposed Changes
Store a schema version in the database so that future releases can check they're running against a compatible database version. This would also enable automatic migration on breaking database changes, but that's left as future work.
The database config is also stored in the database so that the `slots_per_restore_point` value can be checked for consistency, which closes#673
The PR:
* Adds the ability to generate a crucial test scenario that isn't possible with `BeaconChainHarness` (i.e. two blocks occupying the same slot; previously forks necessitated skipping slots):
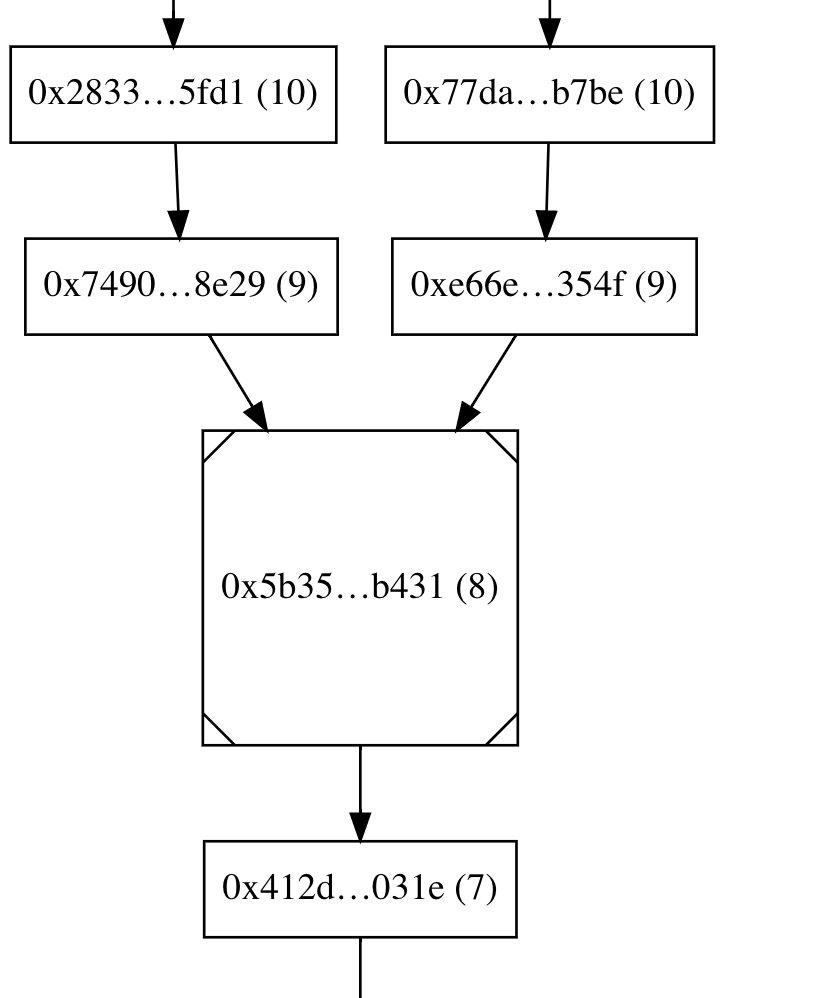
* New testing API: Instead of repeatedly calling add_block(), you generate a sorted `Vec<Slot>` and leave it up to the framework to generate blocks at those slots.
* Jumping backwards to an earlier epoch is a hard error, so that tests necessarily generate blocks in a epoch-by-epoch manner.
* Configures the test logger so that output is printed on the console in case a test fails. The logger also plays well with `--nocapture`, contrary to the existing testing framework
* Rewrites existing fork pruning tests to use the new API
* Adds a tests that triggers finalization at a non epoch boundary slot
* Renamed `BeaconChainYoke` to `BeaconChainTestingRig` because the former has been too confusing
* Fixed multiple tests (e.g. `block_production_different_shuffling_long`, `delete_blocks_and_states`, `shuffling_compatible_simple_fork`) that relied on a weird (and accidental) feature of the old `BeaconChainHarness` that attestations aren't produced for epochs earlier than the current one, thus masking potential bugs in test cases.
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Issue Addressed
Closes#1488
## Proposed Changes
* Prevent the pruning algorithm from over-eagerly deleting states at skipped slots when they are shared with the canonical chain.
* Add `debug` logging to the pruning algorithm so we have so better chance of debugging future issues from logs.
* Modify the handling of the "finalized state" in the beacon chain, so that it's always the state at the first slot of the finalized epoch (previously it was the state at the finalized block). This gives database pruning a clearer and cleaner view of things, and will marginally impact the pruning of the op pool, observed proposers, etc (in ways that are safe as far as I can tell).
* Remove duplicated `RevertedFinalizedEpoch` check from `after_finalization`
* Delete useless and unused `max_finality_distance`
* Add tests that exercise pruning with shared states at skip slots
* Delete unnecessary `block_strategy` argument from `add_blocks` and friends in the test harness (will likely conflict with #1380 slightly, sorry @adaszko -- but we can fix that)
* Bonus: add a `BeaconChain::with_head` method. I didn't end up needing it, but it turned out quite nice, so I figured we could keep it?
## Additional Info
Any users who have experienced pruning errors on Medalla will need to resync after upgrading to a release including this change. This should end unbounded `chain_db` growth! 🎉
## Issue Addressed
NA
## Proposed Changes
- Adds a new function to allow getting a state with a bad state root history for attestation verification. This reduces unnecessary tree hashing during attestation processing, which accounted for 23% of memory allocations (by bytes) in a recent `heaptrack` observation.
- Don't clone caches on intermediate epoch-boundary states during block processing.
- Reject blocks that are known to fork choice earlier during gossip processing, instead of waiting until after state has been loaded (this only happens in edge-case).
- Avoid multiple re-allocations by creating a "forced" exact size iterator.
## Additional Info
NA
{kind=link}