| cmd | ||
| db | ||
| dockerfiles | ||
| documentation | ||
| environments | ||
| integration_test | ||
| libraries/shared | ||
| pkg | ||
| plugins | ||
| scripts | ||
| test_config | ||
| utils | ||
| .dockerignore | ||
| .gitignore | ||
| .travis.yml | ||
| Dockerfile | ||
| go.mod | ||
| LICENSE | ||
| main.go | ||
| Makefile | ||
| README.md | ||
Vulcanize DB

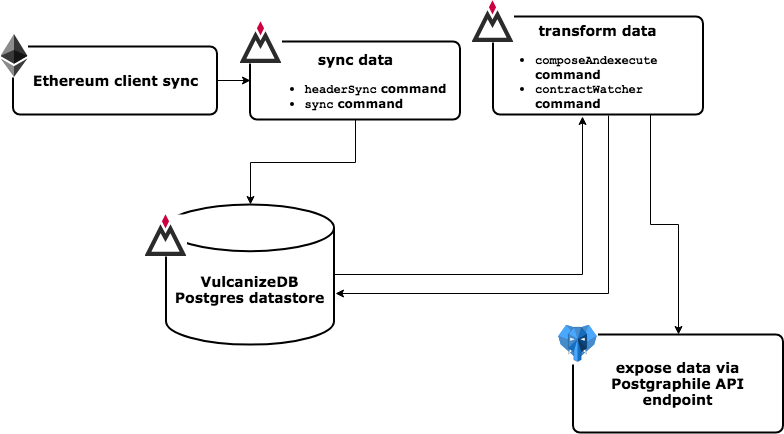
Vulcanize DB is a set of tools that make it easier for developers to write application-specific indexes and caches for dapps built on Ethereum.
Table of Contents
Background
The same data structures and encodings that make Ethereum an effective and trust-less distributed virtual machine complicate data accessibility and usability for dApp developers. VulcanizeDB improves Ethereum data accessibility by providing a suite of tools to ease the extraction and transformation of data into a more useful state, including allowing for exposing aggregate data from a suite of smart contracts.
VulanizeDB includes processes that sync, transform and expose data. Syncing involves querying an Ethereum node and then persisting core data into a Postgres database. Transforming focuses on using previously synced data to query for and transform log event and storage data for specifically configured smart contract addresses. Exposing data is a matter of getting data from VulcanizeDB's underlying Postgres database and making it accessible.
Install
Dependencies
- Go 1.12+
- Postgres 11.2
- Ethereum Node
- Go Ethereum (1.8.23+)
- Parity 1.8.11+
Building the project
Download the codebase to your local GOPATH via:
go get github.com/vulcanize/vulcanizedb
Move to the project directory:
cd $GOPATH/src/github.com/vulcanize/vulcanizedb
Be sure you have enabled Go Modules (export GO111MODULE=on), and build the executable with:
make build
If you need to use a different dependency than what is currently defined in go.mod, it may helpful to look into the replace directive.
This instruction enables you to point at a fork or the local filesystem for dependency resolution.
If you are running into issues at this stage, ensure that GOPATH is defined in your shell.
If necessary, GOPATH can be set in ~/.bashrc or ~/.bash_profile, depending upon your system.
It can be additionally helpful to add $GOPATH/bin to your shell's $PATH.
Setting up the database
-
Install Postgres
-
Create a superuser for yourself and make sure
psql --listworks without prompting for a password. -
createdb vulcanize_public -
cd $GOPATH/src/github.com/vulcanize/vulcanizedb -
Run the migrations:
make migrate HOST_NAME=localhost NAME=vulcanize_public PORT=5432- There is an optional var
USER=usernameif the database user is not the default userpostgres - To rollback a single step:
make rollback NAME=vulcanize_public - To rollback to a certain migration:
make rollback_to MIGRATION=n NAME=vulcanize_public - To see status of migrations:
make migration_status NAME=vulcanize_public
- See below for configuring additional environments
- There is an optional var
In some cases (such as recent Ubuntu systems), it may be necessary to overcome failures of password authentication from localhost. To allow access on Ubuntu, set localhost connections via hostname, ipv4, and ipv6 from peer/md5 to trust in: /etc/postgresql//pg_hba.conf
(It should be noted that trusted auth should only be enabled on systems without sensitive data in them: development and local test databases)
Configuring a synced Ethereum node
- To use a local Ethereum node, copy
environments/public.toml.exampletoenvironments/public.tomland update theipcPathandlevelDbPath.-
ipcPathshould match the local node's IPC filepath:-
For Geth:
- The IPC file is called
geth.ipc. - The geth IPC file path is printed to the console when you start geth.
- The default location is:
- Mac:
<full home path>/Library/Ethereum/geth.ipc - Linux:
<full home path>/ethereum/geth.ipc
- Mac:
- Note: the geth.ipc file may not exist until you've started the geth process
- The IPC file is called
-
For Parity:
- The IPC file is called
jsonrpc.ipc. - The default location is:
- Mac:
<full home path>/Library/Application\ Support/io.parity.ethereum/ - Linux:
<full home path>/local/share/io.parity.ethereum/
- Mac:
- The IPC file is called
-
-
levelDbPathshould match Geth's chaindata directory path.- The geth LevelDB chaindata path is printed to the console when you start geth.
- The default location is:
- Mac:
<full home path>/Library/Ethereum/geth/chaindata - Linux:
<full home path>/ethereum/geth/chaindata
- Mac:
levelDbPathis irrelevant (andcoldImportis currently unavailable) if only running parity.
-
Usage
As mentioned above, VulcanizeDB's processes can be split into three categories: syncing, transforming and exposing data.
Data syncing
To provide data for transformations, raw Ethereum data must first be synced into VulcanizeDB.
This is accomplished through the use of the headerSync, fullSync, or coldImport commands.
These commands are described in detail here.
Data transformation
Data transformation uses the raw data that has been synced into Postgres to filter out and apply transformations to specific data of interest. Since there are different types of data that may be useful for observing smart contracts, it follows that there are different ways to transform this data. We've started by categorizing this into Generic and Custom transformers:
-
Generic Contract Transformer: Generic contract transformation can be done using a built-in command,
contractWatcher, which transforms contract events provided the contract's ABI is available. It also provides some state variable coverage by automating polling of public methods, with some restrictions.contractWatcheris described further here. -
Custom Transformers: In many cases custom transformers will need to be written to provide more comprehensive coverage of contract data. In this case we have provided the
compose,execute, andcomposeAndExecutecommands for running custom transformers from external repositories. Documentation on how to write, build and run custom transformers as Go plugins can be found here.
Exposing the data
Postgraphile is used to expose GraphQL endpoints for our database schemas, this is described in detail here.
Tests
- Replace the empty
ipcPathin theenvironments/testing.tomlwith a path to a full node's eth_jsonrpc endpoint (e.g. local geth node ipc path or infura url)- Note: must be mainnet
- Note: integration tests require configuration with an archival node
make testwill run the unit tests and skip the integration testsmake integrationtestwill run just the integration testsmake testandmake integrationtestsetup a cleanvulcanize_testingdb
Contributing
Contributions are welcome!
VulcanizeDB follows the Contributor Covenant Code of Conduct.
For more information on contributing, please see here.
License
AGPL-3.0 © Vulcanize Inc